rsyslog error reporting improved
Rsyslog provides many up-to-the point error messages for config file and operational problems. These immensly helps when troubleshooting issues. Unfortunately, many users never see them. The prime reason is that most distros do never log syslog.* messages and so they are just throw away and invisible to the user. While we have been trying to make distros change their defaults, this has not been very successful. The result is a lot of user frustration and fruitless support work for the community — many things can very simple be resolved if only the error message is seen and acted on.
We have now changed our approach to this. Starting with v8.21, rsyslog now by default logs its messages via the syslog API instead of processing them internally. This is a big plus especially on systems running systemd journal: messages from rsyslogd will now show up when giving
$ systemctl status rsyslog.service
This is the place where nowadays error messages are expected and this is definitely a place where the typical administrator will see them. So while this change causes the need for some config adjustment on few exotic installations (more below), we expect this to be something that will generally improve the rsyslog user experience.
Along the same lines, we will also work on some better error reporting especially for TLS and queue-related issues, which turn out high in rsyslog suport discussions.
Some fine details on the change of behaviour:
Note: you can usually skip reading the rest of this post if you run only a single instance of rsyslog and do so with more or less default configuration.
The new behaviour was actually available for longer, It needed to be explicitly turned on in rsyslog.conf via
global(processInternalMessages="off")
Of course, distros didn’t do that by default. Also, it required rsyslog to be build with liblogging-stdlog, what many distros do not do. While our intent when we introduced this capability was to provide the better error logging we now have, it simply did not turn out in practice. The original approach was that it was less intrusive. The new method uses the native syslog() API if liblogging-stdlog is not available, so the setting always works (we even consider moving away from liblogging-stdlog, as we see this wasn’t really adopted). In essence, we have primarily changed the default setting for the “processInternalMessages” parameter. This means that by default, internal messages are no longer logged via the internal bridge to rsyslog but via the syslog() API call [either directly or
via liblogging). For the typical single-rsyslogd-instance installation this is mostly unnoticable (except for some additional latency). If multiple instances are run, only the “main” (the one processing system log messages) will see all messages. To return to the old behaviour, do either of those two:
- add in rsyslog.conf:
global(processInternalMessages="on") - export the environment variable
RSYSLOG_DFLT_LOG_INTERNAL=1
This will set a new default – the value can still be overwritten via rsyslog.conf (method 1). Note that the environment variable must be set in your startup script (which one is depending on your init system or systemd configuration).
Note that in most cases even in multiple-instance-setups rsyslog error messages were thrown away. So even in this case the behaviour is superior to the previous state – at least errors are now properly being recorded. This also means that even in multiple-instance-setups it often makes sense to keep the new default!
Using rsyslog to Reindex/Migrate Elasticsearch data
Original post: Scalable and Flexible Elasticsearch Reindexing via rsyslog by @Sematext
This recipe is useful in a two scenarios:
- migrating data from one Elasticsearch cluster to another (e.g. when you’re upgrading from Elasticsearch 1.x to 2.x or later)
- reindexing data from one index to another in a cluster pre 2.3. For clusters on version 2.3 or later, you can use the Reindex API
Back to the recipe, we used an external application to scroll through Elasticsearch documents in the source cluster and push them to rsyslog via TCP. Then we used rsyslog’s Elasticsearch output to push logs to the destination cluster. The overall flow would be:
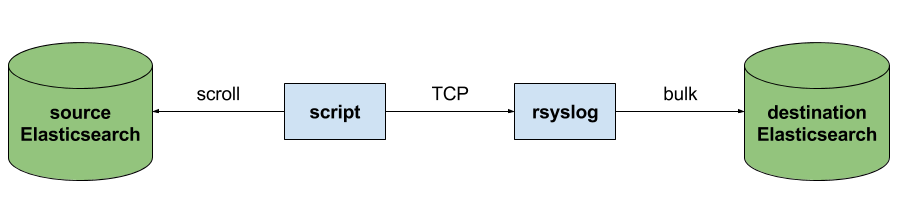
This is an easy way to extend rsyslog, using whichever language you’re comfortable with, to support more inputs. Here, we piggyback on the TCP input. You can do a similar job with filters/parsers – you can find GeoIP implementations, for example – by piggybacking the mmexternal module, which uses stdout&stdin for communication. The same is possible for outputs, normally added via the omprog module: we did this to add a Solr output and one for SPM custom metrics.
The custom script in question doesn’t have to be multi-threaded, you can simply spin up more of them, scrolling different indices. In this particular case, using two scripts gave us slightly better throughput, saturating the network:
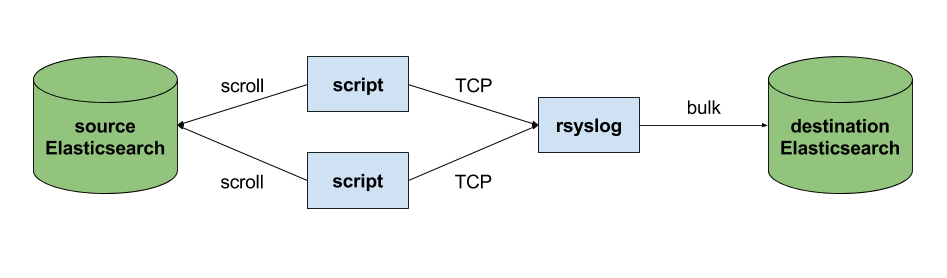
Writing the custom script
Before starting to write the script, one needs to know how the messages sent to rsyslog would look like. To be able to index data, rsyslog will need an index name, a type name and optionally an ID. In this particular case, we were dealing with logs, so the ID wasn’t necessary.
With this in mind, I see a number of ways of sending data to rsyslog:
- one big JSON per line. One can use mmnormalize to parse that JSON, which then allows rsyslog do use values from within it as index name, type name, and so on
- for each line, begin with the bits of “extra data” (like index and type names) then put the JSON document that you want to reindex. Again, you can use mmnormalize to parse, but this time you can simply trust that the last thing is a JSON and send it to Elasticsearch directly, without the need to parse it
- if you only need to pass two variables (index and type name, in this case), you can piggyback on the vague spec of RFC3164 syslog and send something like
destination_index document_type:{"original": "document"}
This last option will parse the provided index name in the hostname variable, the type in syslogtag and the original document in msg. A bit hacky, I know, but quite convenient (makes the rsyslog configuration straightforward) and very fast, since we know the RFC3164 parser is very quick and it runs on all messages anyway. No need for mmnormalize, unless you want to change the document in-flight with rsyslog.
Below you can find the Python code that can scan through existing documents in an index (or index pattern, like logstash_2016.05.*) and push them to rsyslog via TCP. You’ll need the Python Elasticsearch client (pip install elasticsearch) and you’d run it like this:
python elasticsearch_to_rsyslog.py source_index destination_index
The script being:
from elasticsearch import Elasticsearch
import json, socket, sys
source_cluster = ['server1', 'server2']
rsyslog_address = '127.0.0.1'
rsyslog_port = 5514
es = Elasticsearch(source_cluster,
retry_on_timeout=True,
max_retries=10)
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((rsyslog_address, rsyslog_port))
result = es.search(index=sys.argv[1], scroll='1m', search_type='scan', size=500)
while True:
res = es.scroll(scroll_id=result['_scroll_id'], scroll='1m')
for hit in result['hits']['hits']:
s.send(sys.argv[2] + ' ' + hit["_type"] + ':' + json.dumps(hit["_source"])+'\n')
if not result['hits']['hits']:
break
s.close()
If you need to modify messages, you can parse them in rsyslog via mmjsonparse and then add/remove fields though rsyslog’s scripting language. Though I couldn’t find a nice way to change field names – for example to remove the dots that are forbidden since Elasticsearch 2.0 – so I did that in the Python script:
def de_dot(my_dict):
for key, value in my_dict.iteritems():
if '.' in key:
my_dict[key.replace('.','_')] = my_dict.pop(key)
if type(value) is dict:
my_dict[key] = de_dot(my_dict.pop(key))
return my_dict
And then the “send” line becomes:
s.send(sys.argv[2] + ' ' + hit["_type"] + ':' + json.dumps(de_dot(hit["_source"]))+'\n')
Configuring rsyslog
The first step here is to make sure you have the lastest rsyslog, though the config below works with versions all the way back to 7.x (which can be found in most Linux distributions). You just need to make sure the rsyslog-elasticsearch package is installed, because we need the Elasticsearch output module.
# messages bigger than this are truncated
$maxMessageSize 10000000 # ~10MB
# load the TCP input and the ES output modules
module(load="imtcp")
module(load="omelasticsearch")
main_queue(
# buffer up to 1M messages in memory
queue.size="1000000"
# these threads process messages and send them to Elasticsearch
queue.workerThreads="4"
# rsyslog processes messages in batches to avoid queue contention
# this will also be the Elasticsearch bulk size
queue.dequeueBatchSize="4000"
)
# we use templates to specify how the data sent to Elasticsearch looks like
template(name="document" type="list"){
# the "msg" variable contains the document
property(name="msg")
}
template(name="index" type="list"){
# "hostname" has the index name
property(name="hostname")
}
template(name="type" type="list"){
# "syslogtag" has the type name
property(name="syslogtag")
}
# start the TCP listener on the port we pointed the Python script to
input(type="imtcp" port="5514")
# sending data to Elasticsearch, using the templates defined earlier
action(type="omelasticsearch"
template="document"
dynSearchIndex="on" searchIndex="index"
dynSearchType="on" searchType="type"
server="localhost" # destination Elasticsearch host
serverport="9200" # and port
bulkmode="on" # use the bulk API
action.resumeretrycount="-1" # retry indefinitely if Elasticsearch is unreachable
)
This configuration doesn’t have to disturb your local syslog (i.e. by replacing /etc/rsyslog.conf). You can put it someplace else and run a different rsyslog process:
rsyslogd -i /var/run/rsyslog_reindexer.pid -f /home/me/rsyslog_reindexer.conf
And that’s it! With rsyslog started, you can start the Python script(s) and do the reindexing.
Changelog for 8.18.0 (v8-stable)
Version 8.18.0 [v8-stable] 2016-04-19
- testbench: When running privdrop tests testbench tries to drop
user to “rsyslog”, “syslog” or “daemon” when running as root and
you don’t explict set RSYSLOG_TESTUSER environment variable.
Make sure the unprivileged testuser can write into tests/ dir! - templates: add option to convert timestamps to UTC
closes https://github.com/rsyslog/rsyslog/issues/730 - omjournal: fix segfault (regression in 8.17.0)
- imptcp: added AF_UNIX support
Thanks to Nathan Brown for implementing this feature. - new template options
- compressSpace
- date-utc
- redis: support for authentication
Thanks to Manohar Ht for the patch - omkafka: makes kafka-producer on-HUP restart optional
As of now, omkafka kills and re-creates kafka-producer on HUP. This
is not always desirable. This change introduces an action param
(reopenOnHup=”on|off”) which allows user to control re-cycling of
kafka-producer.
It defaults to on (for backward compatibility). Off allows user to
ignore HUP as far as kafka-producer is concerned.
Thanks to Janmejay Singh for implementing this feature - imfile: new “FreshStartTail” input parameter
Thanks to Curu Wong for implementing this. - omjournal: fix libfastjson API issues
This module accessed private data members of libfastjson - ommongodb: fix json API issues
This module accessed private data members of libfastjson - testbench improvements (more tests and more thourough tests)
among others:- tests for omjournal added
- tests for KSI subsystem
- tests for priviledge drop statements
- basic test for RELP with TLS
- some previously disabled tests have been re-enabled
- dynamic stats subsystem: a couple of smaller changes
they also involve the format, which is slightly incompatible to
previous version. As this was out only very recently (last version),
we considered this as acceptable.
Thanks to Janmejay Singh for developing this. - foreach loop: now also iterates over objects (not just arrays)
Thanks to Janmejay Singh for developing this. - improvements to the CI environment
- enhancement: queue subsystem is more robst in regard to some corruptions
It is now detected if a .qi file states that the queue contains more
records than there are actually inside the queue files. Previously this
resulted in an emergency switch to direct mode, now the problem is only
reported but processing continues. - enhancement: Allow rsyslog to bind UDP ports even w/out specific
interface being up at the moment.
Alternatively, rsyslog could be ordered after networking, however,
that might have some negative side effects. Also IP_FREEBIND is
recommended by systemd documentation.
Thanks to Nirmoy Das and Marius Tomaschewski for the patch. - cleanup: removed no longer needed json-c compatibility layer
as we now always use libfastjson, we do not need to support old
versions of json-c (libfastjson was based on the newest json-c
version at the time of the fork, which is the newest in regard
to the compatibility layer) - new External plugin for sending metrics to SPM Monitoring SaaS
Thanks to Radu Gheorghe for the patch. - bugfix imfile: fix memory corruption bug when appending @cee
Thanks to Brian Knox for the patch. - bugfix: memory misallocation if position.from and position.to is used
a negative amount of memory is tried to be allocated if position.from
is smaller than the buffer size (at least with json variables). This
usually leads to a segfault.
closes https://github.com/rsyslog/rsyslog/issues/915 - bugfix: fix potential memleak in TCP allowed sender definition
depending on circumstances, a very small leak could happen on each
HUP. This was caused by an invalid macro definition which did not rule
out side effects. - bugfix: $PrivDropToGroupID actually did a name lookup
… instead of using the provided ID - bugfix: small memory leak in imfile
Thanks to Tomas Heinrich for the patch. - bugfix: double free in jsonmesg template
There has to be actual json data in the message (from mmjsonparse,
mmnormalize, imjournal, …) to trigger the crash.
Thanks to Tomas Heinrich for the patch. - bugfix: incorrect formatting of stats when CEE/Json format is used
This lead to ill-formed json being generated - bugfix omfwd: new-style keepalive action parameters did not work
due to being inconsistently spelled inside the code. Note that legacy
parameters $keepalive… always worked
see also: https://github.com/rsyslog/rsyslog/issues/916
Thanks to Devin Christensen for alerting us and an analysis of the
root cause. - bugfix: memory leaks in logctl utility
Detected by clang static analyzer. Note that these leaks CAN happen in
practice and may even be pretty large. This was probably never detected
because the tool is not often used. - bugfix omrelp: fix segfault if no port action parameter was given
closes https://github.com/rsyslog/rsyslog/issues/911 - bugfix imtcp: Messages not terminated by a NL were discarded
… upon connection termination.
Thanks to Tomas Heinrich for the patch.
Monitoring rsyslog’s impstats with Kibana and SPM
Original post: Monitoring rsyslog with Kibana and SPM by @Sematext
A while ago we published this post where we explained how you can get stats about rsyslog, such as the number of messages enqueued, the number of output errors and so on. The point was to send them to Elasticsearch (or Logsene, our logging SaaS, which exposes the Elasticsearch API) in order to analyze them.
This is part 2 of that story, where we share how we process these stats in production. We’ll cover:
- an updated config, working with Elasticsearch 2.x
- what Kibana dashboards we have in Logsene to get an overview of what rsyslog is doing
- how we send some of these metrics to SPM as well, in order to set up alerts on their values: both threshold-based alerts and anomaly detection
Continue reading “Monitoring rsyslog’s impstats with Kibana and SPM”
RSyslog Windows Agent 3.2 Released
Adiscon is proud to announce the 3.2 release of RSyslog Windows Agent.
This is a maintenenance release for RSyslog Windows Agent, which includes Features and bugfixes.
There is a huge list of changes, but the most important is the enhanced support for file based configurations.
Also inbuild components like OpenSSL and NetSNMP have been updated to the latest versions.
Detailed information can be found in the version history below.
Build-IDs: Service 3.2.143, Client 3.2.0.230
Features |
|
Bugfixes |
|
Version 3.2 is a free download. Customers with existing 2.x keys can contact our Sales department for upgrade prices. If you have a valid Upgrade Insurance ID, you can request a free new key by sending your Upgrade Insurance ID to sales@adiscon.com. Please note that the download enables the free 30-day trial version if used without a key – so you can right now go ahead and evaluate it.
Changelog for 8.17.0 (v8-stable)
Version 8.17.0 [v8-stable] 2016-03-08
- NEW REQUIREMENT: libfastjson
see also:
http://blog.gerhards.net/2015/12/rsyslog-and-liblognorm-will-switch-to.html - new testbench requirement: faketime command line tool
This is used to generate a controlled environment for time-based tests; if
not available, tests will gracefully be skipped. - improve json variable performance
We use libfastjson’s alternative hash function, which has been
proven to be much faster than the default one (which stems
back to libjson-c). This should bring an overall performance
improvement for all operations involving variable processing.
closes https://github.com/rsyslog/rsyslog/issues/848 - new experimental feature: lookup table suport
Note that at this time, this is an experimental feature which is not yet
fully supported by the rsyslog team. It is introduced in order to gain
more feedback and to make it available as early as possible because many
people consider it useful.
Thanks to Janmejay Singh for implementing this feature - new feature: dynamic statistics counters
which may be changed during rule processing
Thanks to Janmejay Singh for suggesting and implementing this feature - new contributed plugin: omampq1 for AMQP 1.0-compliant brokers
Thanks to Ken Giusti for this module - new set of UTC-based $now family of variables ($now-utc, $year-utc, …)
- simplified locking when accessing message and local variables
this simlifies the code and slightly increases performance if such
variables are heavily accessed. - new global parameter “debug.unloadModules”
This permits to disable unloading of modules, e.g. to make valgrind
reports more useful (without a need to recompile). - timestamp handling: guard against invalid dates
We do not permit dates outside of the year 1970..2100
interval. Note that network-receivers do already guard
against this, so the new guard only guards against invalid
system time. - imfile: add “trimlineoverbytes” input paramter
Thanks to github user JindongChen for the patch. - ommongodb: add support for extended json format for dates
Thanks to Florian Bücklers for the patch. - omjournal: add support for templates
see also: https://github.com/rsyslog/rsyslog/pull/770
Thanks to github user bobthemighty for the patch - imuxsock: add “ruleset” input parameter
- testbench: framework improvement: configs can be included in test file
they do no longer need to be in a separate file, which saves a bit
of work when working with them. This is supported for simple tests with
a single running rsyslog instance
Thanks to Janmejay Singh for inspiring me with a similar method in
liblognorm testbench. - imptcp: performance improvements
Thanks to Janmejay Singh for implementing this improvement - made build compile (almost) without warnings
still some warnings are suppressed where this is currently required - improve interface definition in some modules, e.g. mmanon, mmsequence
This is more an internal cleanup and should have no actual affect to
the end user. - solaris build: MAXHOSTNAMELEN properly detected
- build system improvement: ability to detect old hiredis libs
This permits to automatically build omhiredis on systems where the
hiredis libs do not provide a pkgconfig file. Previsouly, this
required manual configuration.
Thanks to github user jaymell for the patch. - rsgtutil: dump mode improvements
- auto-detect signature file type
- ability to dump hash chains for log extraction files
- build system: fix build issues with clang
clang builds often failed with a missing external symbol
“rpl_malloc”. This was caused by checks in configure.ac,
which checked for specific GNU semantics. As we do not need
them (we never ask malloc for zero bytes), we can safely
remove the macros.
Note that we routinely run clang static analyer in CI and
it also detects such calls as invalid.
closes https://github.com/rsyslog/rsyslog/issues/834 - bugfix: unixtimestamp date format was incorrectly computed
The problem happened in leap year from March til then end
of year and healed itself at the begining of the next year.
During the problem period, the timestamp was 24 hours too low.
fixes https://github.com/rsyslog/rsyslog/issues/830 - bugfix: date-ordinal date format was incorrectly computed
same root cause aus for unixtimestamp and same triggering
condition. During the affected perido, the ordinal was one
too less. - bugfix: some race when shutting down input module threads
this had little, if at all, effect on real deployments as it resulted
in a small leak right before rsyslog termination. However, it caused
trouble with the testbench (and other QA tools).
Thanks to Peter Portante for the patch and both Peter and Janmejay
Singh for helping to analyze what was going on. - bugfix tcpflood: did not handle connection drops correct in TLS case
note that tcpflood is a testbench too. The bug caused some testbench
instability, but had no effect on deplyments. - bugfix: abort if global parameter value was wrong
If so, the abort happened during startup. Once started,
all was stable. - bugfix omkafka: fix potential NULL pointer addressing
this happened when the topic cache was full and an entry
needed to be evicted - bugfix impstats: @cee cookie was prefixed to wrong fromat (json vs. cee)
Thanks to Volker Fröhlich for the fix. - bugfix imfile: fix race during startup that could lead to some duplication
If a to-be-monitored file was created after inotify was initialized
but before startup was completed, the first chunk of data from this
file could be duplicated. This should have happened very rarely in
practice, but caused occasional testbench failures.
see also: https://github.com/rsyslog/rsyslog/issues/791 - bugfix: potential loss of single message at queue shutdown
see also: https://github.com/rsyslog/rsyslog/issues/262 - bugfix: potential deadlock with heavy variable access
When making havy use of global, local and message variables, a deadlock
could occur. While it is extremly unlikely to happen, we have at least
seen one incarnation of this problem in practice. - bugfix ommysql: on some platforms, serverport parameter had no effect
This was caused by an invalid code sequence which’s outcome depends on
compiler settings. - bugfix omelasticsearch: invalid pointer dereference
The actual practical impact is not clear. This came up when working
on compiler warnings.
Thanks to David Lang for the patch. - bugfix omhiredis: serverport config parameter did not reliably work
depended on environment/compiler used to build - bugfix rsgtutil: -h command line option did not work
Thanks to Henri Lakk for the patch. - bugfix lexer: hex numbers were not properly represented
see: https://github.com/rsyslog/rsyslog/pull/771
Thanks to Sam Hanes for the patch. - bugfix TLS syslog: intermittent errors while sending data
Regression from commit 1394e0b. A symptom often seen was the message
“unexpected GnuTLS error -50 in nsd_gtls.c:530” - bugfix imfile: abort on startup if no slash was present in file name param
Thanks to Brian Knox for the patch. - bugfix rsgtutil: fixed abort when using short command line options
Thanks to Henri Lakk - bugfix rsgtutil: invalid computation of log record extraction file
This caused verification to fail because the hash chain was actually
incorrect. Depended on the input data set.
closes https://github.com/rsyslog/rsyslog/issues/832 - bugfix build system: KSI components could only be build if in default path
Connecting with Logstash via Apache Kafka
Original post: Recipe: rsyslog + Kafka + Logstash by @Sematext
This recipe is similar to the previous rsyslog + Redis + Logstash one, except that we’ll use Kafka as a central buffer and connecting point instead of Redis. You’ll have more of the same advantages:
- rsyslog is light and crazy-fast, including when you want it to tail files and parse unstructured data (see the Apache logs + rsyslog + Elasticsearch recipe)
- Kafka is awesome at buffering things
- Logstash can transform your logs and connect them to N destinations with unmatched ease
There are a couple of differences to the Redis recipe, though:
- rsyslog already has Kafka output packages, so it’s easier to set up
- Kafka has a different set of features than Redis (trying to avoid flame wars here) when it comes to queues and scaling
As with the other recipes, I’ll show you how to install and configure the needed components. The end result would be that local syslog (and tailed files, if you want to tail them) will end up in Elasticsearch, or a logging SaaS like Logsene (which exposes the Elasticsearch API for both indexing and searching). Of course you can choose to change your rsyslog configuration to parse logs as well (as we’ve shown before), and change Logstash to do other things (like adding GeoIP info).
Getting the ingredients
First of all, you’ll probably need to update rsyslog. Most distros come with ancient versions and don’t have the plugins you need. From the official packages you can install:
- rsyslog. This will update the base package, including the file-tailing module
- rsyslog-kafka. This will get you the Kafka output module
If you don’t have Kafka already, you can set it up by downloading the binary tar. And then you can follow the quickstart guide. Basically you’ll have to start Zookeeper first (assuming you don’t have one already that you’d want to re-use):
bin/zookeeper-server-start.sh config/zookeeper.properties
And then start Kafka itself and create a simple 1-partition topic that we’ll use for pushing logs from rsyslog to Logstash. Let’s call it rsyslog_logstash:
bin/kafka-server-start.sh config/server.properties bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic rsyslog_logstash
Finally, you’ll have Logstash. At the time of writing this, we have a beta of 2.0, which comes with lots of improvements (including huge performance gains of the GeoIP filter I touched on earlier). After downloading and unpacking, you can start it via:
bin/logstash -f logstash.conf
Though you also have packages, in which case you’d put the configuration file in /etc/logstash/conf.d/ and start it with the init script.
Configuring rsyslog
With rsyslog, you’d need to load the needed modules first:
module(load="imuxsock") # will listen to your local syslog module(load="imfile") # if you want to tail files module(load="omkafka") # lets you send to Kafka
If you want to tail files, you’d have to add definitions for each group of files like this:
input(type="imfile" File="/opt/logs/example*.log" Tag="examplelogs" )
Then you’d need a template that will build JSON documents out of your logs. You would publish these JSON’s to Kafka and consume them with Logstash. Here’s one that works well for plain syslog and tailed files that aren’t parsed via mmnormalize:
template(name="json_lines" type="list" option.json="on") {
constant(value="{")
constant(value="\"timestamp\":\"")
property(name="timereported" dateFormat="rfc3339")
constant(value="\",\"message\":\"")
property(name="msg")
constant(value="\",\"host\":\"")
property(name="hostname")
constant(value="\",\"severity\":\"")
property(name="syslogseverity-text")
constant(value="\",\"facility\":\"")
property(name="syslogfacility-text")
constant(value="\",\"syslog-tag\":\"")
property(name="syslogtag")
constant(value="\"}")
}
By default, rsyslog has a memory queue of 10K messages and has a single thread that works with batches of up to 16 messages (you can find all queue parameters here). You may want to change:
– the batch size, which also controls the maximum number of messages to be sent to Kafka at once
– the number of threads, which would parallelize sending to Kafka as well
– the size of the queue and its nature: in-memory(default), disk or disk-assisted
In a rsyslog->Kafka->Logstash setup I assume you want to keep rsyslog light, so these numbers would be small, like:
main_queue( queue.workerthreads="1" # threads to work on the queue queue.dequeueBatchSize="100" # max number of messages to process at once queue.size="10000" # max queue size )
Finally, to publish to Kafka you’d mainly specify the brokers to connect to (in this example we have one listening to localhost:9092) and the name of the topic we just created:
action( broker=["localhost:9092"] type="omkafka" topic="rsyslog_logstash" template="json" )
Assuming Kafka is started, rsyslog will keep pushing to it.
Configuring Logstash
This is the part where we pick the JSON logs (as defined in the earlier template) and forward them to the preferred destinations. First, we have the input, which will use to the Kafka topic we created. To connect, we’ll point Logstash to Zookeeper, and it will fetch all the info about Kafka from there:
input {
kafka {
zk_connect => "localhost:2181"
topic_id => "rsyslog_logstash"
}
}
At this point, you may want to use various filters to change your logs before pushing to Logsene/Elasticsearch. For this last step, you’d use the Elasticsearch output:
output {
elasticsearch {
hosts => "localhost" # it used to be "host" pre-2.0
port => 9200
#ssl => "true"
#protocol => "http" # removed in 2.0
}
}
And that’s it! Now you can use Kibana (or, in the case of Logsene, either Kibana or Logsene’s own UI) to search your logs!
Recipe: Apache Logs + rsyslog (parsing) + Elasticsearch
Original post: Recipe: Apache Logs + rsyslog (parsing) + Elasticsearch by @Sematext
This recipe is about tailing Apache HTTPD logs with rsyslog, parsing them into structured JSON documents, and forwarding them to Elasticsearch (or a log analytics SaaS, like Logsene, which exposes the Elasticsearch API). Having them indexed in a structured way will allow you to do better analytics with tools like Kibana:

We’ll also cover pushing logs coming from the syslog socket and kernel, and how to buffer all of them properly. So this is quite a complete recipe for your centralized logging needs.
Getting the ingredients
Even though most distros already have rsyslog installed, it’s highly recommended to get the latest stable from the rsyslog repositories. The packages you’ll need are:
- rsyslog. The base package, including the file-tailing module (imfile)
- rsyslog-mmnormalize. This gives you mmnormalize, a module that will do the parsing of common Apache logs to JSON
- rsyslog-elasticsearch, for the Elasticsearch output
With the ingredients in place, let’s start cooking a configuration. The configuration needs to do the following:
- load the required modules
- configure inputs: tailing Apache logs and system logs
- configure the main queue to buffer your messages. This is also the place to define the number of worker threads and batch sizes (which will also be Elasticsearch bulk sizes)
- parse common Apache logs into JSON
- define a template where you’d specify how JSON messages would look like. You’d use this template to send logs to Logsene/Elasticsearch via the Elasticsearch output
Loading modules
Here, we’ll need imfile to tail files, mmnormalize to parse them, and omelasticsearch to send them. If you want to tail the system logs, you’d also need to include imuxsock and imklog (for kernel logs).
# system logs module(load="imuxsock") module(load="imklog") # file module(load="imfile") # parser module(load="mmnormalize") # sender module(load="omelasticsearch")
Configure inputs
For system logs, you typically don’t need any special configuration (unless you want to listen to a non-default Unix Socket). For Apache logs, you’d point to the file(s) you want to monitor. You can use wildcards for file names as well. You also need to specify a syslog tag for each input. You can use this tag later for filtering.
input(type="imfile"
File="/var/log/apache*.log"
Tag="apache:"
)NOTE: By default, rsyslog will not poll for file changes every N seconds. Instead, it will rely on the kernel (via inotify) to poke it when files get changed. This makes the process quite realtime and scales well, especially if you have many files changing rarely. Inotify is also less prone to bugs when it comes to file rotation and other events that would otherwise happen between two “polls”. You can still use the legacy mode=”polling” by specifying it in imfile’s module parameters.
Queue and workers
By default, all incoming messages go into a main queue. You can also separate flows (e.g. files and system logs) by using different rulesets but let’s keep it simple for now.
For tailing files, this kind of queue would work well:
main_queue( queue.workerThreads="4" queue.dequeueBatchSize="1000" queue.size="10000" )
This would be a small in-memory queue of 10K messages, which works well if Elasticsearch goes down, because the data is still in the file and rsyslog can stop tailing when the queue becomes full, and then resume tailing. 4 worker threads will pick batches of up to 1000 messages from the queue, parse them (see below) and send the resulting JSONs to Elasticsearch.
If you need a larger queue (e.g. if you have lots of system logs and want to make sure they’re not lost), I would recommend using a disk-assisted memory queue, that will spill to disk whenever it uses too much memory:
main_queue( queue.workerThreads="4" queue.dequeueBatchSize="1000" queue.highWatermark="500000" # max no. of events to hold in memory queue.lowWatermark="200000" # use memory queue again, when it's back to this level queue.spoolDirectory="/var/run/rsyslog/queues" # where to write on disk queue.fileName="stats_ruleset" queue.maxDiskSpace="5g" # it will stop at this much disk space queue.size="5000000" # or this many messages queue.saveOnShutdown="on" # save memory queue contents to disk when rsyslog is exiting )
Parsing with mmnormalize
The message normalization module uses liblognorm to do the parsing. So in the configuration you’d simply point rsyslog to the liblognorm rulebase:
action(type="mmnormalize" rulebase="/opt/rsyslog/apache.rb" )
where apache.rb will contain rules for parsing apache logs, that can look like this:
version=2 rule=:%clientip:word% %ident:word% %auth:word% [%timestamp:char-to:]%] "%verb:word% %request:word% HTTP/%httpversion:float%" %response:number% %bytes:number% "%referrer:char-to:"%" "%agent:char-to:"%"%blob:rest%
Where version=2 indicates that rsyslog should use liblognorm’s v2 engine (which is was introduced in rsyslog 8.13) and then you have the actual rule for parsing logs. You can find more details about configuring those rules in the liblognorm documentation.
Besides parsing Apache logs, creating new rules typically requires a lot of trial and error. To check your rules without messing with rsyslog, you can use the lognormalizer binary like:
head -1 /path/to/log.file | /usr/lib/lognorm/lognormalizer -r /path/to/rulebase.rb -e json
NOTE: If you’re used to Logstash’s grok, this kind of parsing rules will look very familiar. However, things are quite different under the hood. Grok is a nice abstraction over regular expressions, while liblognorm builds parse trees out of specialized parsers. This makes liblognorm much faster, especially as you add more rules. In fact, it scales so well, that for all practical purposes, performance depends on the length of the log lines and not on the number of rules. This post explains the theory behind this assuption, and this is actually proven by various tests. The downside is that you’ll lose some of the flexibility offered by regular expressions. You can still use regular expressions with liblognorm (you’d need to set allow_regex to on when loading mmnormalize) but then you’d lose a lot of the benefits that come with the parse tree approach.
Template for parsed logs
Since we want to push logs to Elasticsearch as JSON, we’d need to use templates to format them. For Apache logs, by the time parsing ended, you already have all the relevant fields in the $!all-json variable, that you’ll use as a template:
template(name="all-json" type="list"){
property(name="$!all-json")
}Template for time-based indices
For the logging use-case, you’d probably want to use time-based indices (e.g. if you keep your logs for 7 days, you can have one index per day). Such a design will give your cluster a lot more capacity due to the way Elasticsearch merges data in the background (you can learn the details in our presentations at GeeCON and Berlin Buzzwords).
To make rsyslog use daily or other time-based indices, you need to define a template that builds an index name off the timestamp of each log. This is one that names them logstash-YYYY.MM.DD, like Logstash does by default:
template(name="logstash-index"
type="list") {
constant(value="logstash-")
property(name="timereported" dateFormat="rfc3339" position.from="1" position.to="4")
constant(value=".")
property(name="timereported" dateFormat="rfc3339" position.from="6" position.to="7")
constant(value=".")
property(name="timereported" dateFormat="rfc3339" position.from="9" position.to="10")
}And then you’d use this template in the Elasticsearch output:
action(type="omelasticsearch" template="all-json" dynSearchIndex="on" searchIndex="logstash-index" searchType="apache" server="MY-ELASTICSEARCH-SERVER" bulkmode="on" action.resumeretrycount="-1" )
Putting both Apache and system logs together
If you use the same rsyslog to parse system logs, mmnormalize won’t parse them (because they don’t match Apache’s common log format). In this case, you’ll need to pick the rsyslog properties you want and build an additional JSON template:
template(name="plain-syslog"
type="list") {
constant(value="{")
constant(value="\"timestamp\":\"") property(name="timereported" dateFormat="rfc3339")
constant(value="\",\"host\":\"") property(name="hostname")
constant(value="\",\"severity\":\"") property(name="syslogseverity-text")
constant(value="\",\"facility\":\"") property(name="syslogfacility-text")
constant(value="\",\"tag\":\"") property(name="syslogtag" format="json")
constant(value="\",\"message\":\"") property(name="msg" format="json")
constant(value="\"}")
}Then you can make rsyslog decide: if a log was parsed successfully, use the all-json template. If not, use the plain-syslog one:
if $parsesuccess == "OK" then {
action(type="omelasticsearch"
template="all-json"
...
)
} else {
action(type="omelasticsearch"
template="plain-syslog"
...
)
}And that’s it! Now you can restart rsyslog and get both your system and Apache logs parsed, buffered and indexed into Elasticsearch. If you’re a Logsene user, the recipe is a bit simpler: you’d follow the same steps, except that you’ll skip the logstash-index template (Logsene does that for you) and your Elasticsearch actions will look like this:
action(type="omelasticsearch" template="all-json or plain-syslog" searchIndex="LOGSENE-APP-TOKEN-GOES-HERE" searchType="apache" server="logsene-receiver.sematext.com" serverport="80" bulkmode="on" action.resumeretrycount="-1" )
Coupling with Logstash via Redis
Original post: Recipe: rsyslog + Redis + Logstash by @Sematext
OK, so you want to hook up rsyslog with Logstash. If you don’t remember why you want that, let me give you a few hints:
- Logstash can do lots of things, it’s easy to set up but tends to be too heavy to put on every server
- you have Redis already installed so you can use it as a centralized queue. If you don’t have it yet, it’s worth a try because it’s very light for this kind of workload.
- you have rsyslog on pretty much all your Linux boxes. It’s light and surprisingly capable, so why not make it push to Redis in order to hook it up with Logstash?
In this post, you’ll see how to install and configure the needed components so you can send your local syslog (or tail files with rsyslog) to be buffered in Redis so you can use Logstash to ship them to Elasticsearch, a logging SaaS like Logsene (which exposes the Elasticsearch API for both indexing and searching) so you can search and analyze them with Kibana:

Changelog for 8.11.0 (v8-stable)
Version 8.11.0 [v8-stable] 2015-06-30
- new signature provider for Keyless Signature Infrastructure (KSI) added
- build system: re-enable use of “make distcheck”
- bugfix imfile: regex multiline mode ignored escapeLF option
Thanks to Ciprian Hacman for reporting the problem
closes https://github.com/rsyslog/rsyslog/issues/370 - bugfix omkafka: fixed several concurrency issues, most of them related to dynamic topics.
Thanks to Janmejay Singh for the patch. - bugfix: execonlywhenpreviousissuspende
d did not work correctly
This especially caused problems when an action with this attribute was configured with an action queue. - bugfix core engine: ensured global variable atomicity
This could lead to problems in RainerScript, as well as probably in other areas where global variables are used inside rsyslog. I wouldn’t outrule it could lead to segfaults.
Thanks to Janmejay Singh for the patch. - bugfix imfile: segfault when using startmsg.regex because of empty log line
closes https://github.com/rsyslog/rsyslog/issues/357
Thanks to Ciprian Hacman for the patch. - bugfix: build problem on Solaris
Thanks to Dagobert Michelsen for reporting this and getting us up to
speed on the openCWS build farm. - bugfix: build system strndup was used even if not present now added compatibility function. This came up on Solaris builds.
Thanks to Dagobert Michelsen for reporting the problem.
closes https://github.com/rsyslog/rsyslog/issues/347