rsyslog 8.24.0 (v8-stable) released
We have released rsyslog 8.24.0.
This first release for 2017 brings a lot of changes. Most are detail enhancements for different modules. The biggest change is probably, that rsyslog now builds on the AIX platform. Also 8.24.0 has two new message modification modules, which might be worth checking out. And a very useful addition is the ability to bind imudp and omfwd to a specific device.
For a complete list of changes, fixes and enhancements, please visit the ChangeLog.
https://github.com/rsyslog/rsyslog/blob/v8-stable/ChangeLog
Download:
http://www.rsyslog.com/downloads/download-v8-stable/
As always, feedback is appreciated.
Best regards,
Florian Riedl
rsyslog 8.23.0 (v8-stable) released
We have released rsyslog 8.23.0.
This release is packed with changes and enhancements. One of the most interesting might be the removal of the SHA2-224 hash algorithm for KSI signatures. This is considered insecure and is no longer supported by the KSI library. Also notable are the changes to imfile, omfile and omelasticsearch, among lots of others. Please take a look at the Changelog for a full overview.
https://github.com/rsyslog/rsyslog/blob/v8-stable/ChangeLog
Download:
http://www.rsyslog.com/downloads/download-v8-stable/
As always, feedback is appreciated.
Best regards,
Florian Riedl
rsyslog 8.19.0 (v8-stable) released
We have released rsyslog 8.19.0.
This is mostly a bug-fixing release. Among the big number of fixes are a few additions to the testbench and some minor enhancements for several modules (like imrelp, omelasticsearch) to provide more convenience.
https://github.com/rsyslog/rsyslog/blob/v8-stable/ChangeLog
Download:
http://www.rsyslog.com/downloads/download-v8-stable/
As always, feedback is appreciated.
Best regards,
Florian Riedl
Using rsyslog to Reindex/Migrate Elasticsearch data
Original post: Scalable and Flexible Elasticsearch Reindexing via rsyslog by @Sematext
This recipe is useful in a two scenarios:
- migrating data from one Elasticsearch cluster to another (e.g. when you’re upgrading from Elasticsearch 1.x to 2.x or later)
- reindexing data from one index to another in a cluster pre 2.3. For clusters on version 2.3 or later, you can use the Reindex API
Back to the recipe, we used an external application to scroll through Elasticsearch documents in the source cluster and push them to rsyslog via TCP. Then we used rsyslog’s Elasticsearch output to push logs to the destination cluster. The overall flow would be:
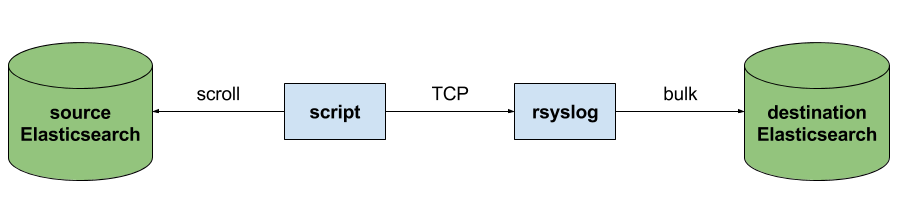
This is an easy way to extend rsyslog, using whichever language you’re comfortable with, to support more inputs. Here, we piggyback on the TCP input. You can do a similar job with filters/parsers – you can find GeoIP implementations, for example – by piggybacking the mmexternal module, which uses stdout&stdin for communication. The same is possible for outputs, normally added via the omprog module: we did this to add a Solr output and one for SPM custom metrics.
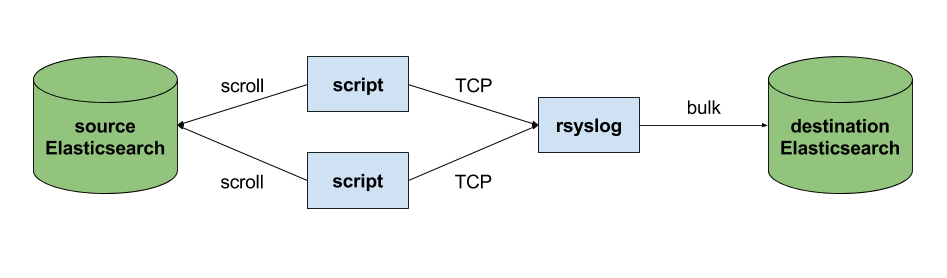
The custom script in question doesn’t have to be multi-threaded, you can simply spin up more of them, scrolling different indices. In this particular case, using two scripts gave us slightly better throughput, saturating the network:
Writing the custom script
Before starting to write the script, one needs to know how the messages sent to rsyslog would look like. To be able to index data, rsyslog will need an index name, a type name and optionally an ID. In this particular case, we were dealing with logs, so the ID wasn’t necessary.
With this in mind, I see a number of ways of sending data to rsyslog:
- one big JSON per line. One can use mmnormalize to parse that JSON, which then allows rsyslog do use values from within it as index name, type name, and so on
- for each line, begin with the bits of “extra data” (like index and type names) then put the JSON document that you want to reindex. Again, you can use mmnormalize to parse, but this time you can simply trust that the last thing is a JSON and send it to Elasticsearch directly, without the need to parse it
- if you only need to pass two variables (index and type name, in this case), you can piggyback on the vague spec of RFC3164 syslog and send something like
destination_index document_type:{"original": "document"}
This last option will parse the provided index name in the hostname variable, the type in syslogtag and the original document in msg. A bit hacky, I know, but quite convenient (makes the rsyslog configuration straightforward) and very fast, since we know the RFC3164 parser is very quick and it runs on all messages anyway. No need for mmnormalize, unless you want to change the document in-flight with rsyslog.
Below you can find the Python code that can scan through existing documents in an index (or index pattern, like logstash_2016.05.*) and push them to rsyslog via TCP. You’ll need the Python Elasticsearch client (pip install elasticsearch) and you’d run it like this:
python elasticsearch_to_rsyslog.py source_index destination_index
The script being:
from elasticsearch import Elasticsearch
import json, socket, sys
source_cluster = ['server1', 'server2']
rsyslog_address = '127.0.0.1'
rsyslog_port = 5514
es = Elasticsearch(source_cluster,
retry_on_timeout=True,
max_retries=10)
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((rsyslog_address, rsyslog_port))
result = es.search(index=sys.argv[1], scroll='1m', search_type='scan', size=500)
while True:
res = es.scroll(scroll_id=result['_scroll_id'], scroll='1m')
for hit in result['hits']['hits']:
s.send(sys.argv[2] + ' ' + hit["_type"] + ':' + json.dumps(hit["_source"])+'\n')
if not result['hits']['hits']:
break
s.close()
If you need to modify messages, you can parse them in rsyslog via mmjsonparse and then add/remove fields though rsyslog’s scripting language. Though I couldn’t find a nice way to change field names – for example to remove the dots that are forbidden since Elasticsearch 2.0 – so I did that in the Python script:
def de_dot(my_dict):
for key, value in my_dict.iteritems():
if '.' in key:
my_dict[key.replace('.','_')] = my_dict.pop(key)
if type(value) is dict:
my_dict[key] = de_dot(my_dict.pop(key))
return my_dict
And then the “send” line becomes:
s.send(sys.argv[2] + ' ' + hit["_type"] + ':' + json.dumps(de_dot(hit["_source"]))+'\n')
Configuring rsyslog
The first step here is to make sure you have the lastest rsyslog, though the config below works with versions all the way back to 7.x (which can be found in most Linux distributions). You just need to make sure the rsyslog-elasticsearch package is installed, because we need the Elasticsearch output module.
# messages bigger than this are truncated
$maxMessageSize 10000000 # ~10MB
# load the TCP input and the ES output modules
module(load="imtcp")
module(load="omelasticsearch")
main_queue(
# buffer up to 1M messages in memory
queue.size="1000000"
# these threads process messages and send them to Elasticsearch
queue.workerThreads="4"
# rsyslog processes messages in batches to avoid queue contention
# this will also be the Elasticsearch bulk size
queue.dequeueBatchSize="4000"
)
# we use templates to specify how the data sent to Elasticsearch looks like
template(name="document" type="list"){
# the "msg" variable contains the document
property(name="msg")
}
template(name="index" type="list"){
# "hostname" has the index name
property(name="hostname")
}
template(name="type" type="list"){
# "syslogtag" has the type name
property(name="syslogtag")
}
# start the TCP listener on the port we pointed the Python script to
input(type="imtcp" port="5514")
# sending data to Elasticsearch, using the templates defined earlier
action(type="omelasticsearch"
template="document"
dynSearchIndex="on" searchIndex="index"
dynSearchType="on" searchType="type"
server="localhost" # destination Elasticsearch host
serverport="9200" # and port
bulkmode="on" # use the bulk API
action.resumeretrycount="-1" # retry indefinitely if Elasticsearch is unreachable
)
This configuration doesn’t have to disturb your local syslog (i.e. by replacing /etc/rsyslog.conf). You can put it someplace else and run a different rsyslog process:
rsyslogd -i /var/run/rsyslog_reindexer.pid -f /home/me/rsyslog_reindexer.conf
And that’s it! With rsyslog started, you can start the Python script(s) and do the reindexing.
Monitoring rsyslog’s impstats with Kibana and SPM
Original post: Monitoring rsyslog with Kibana and SPM by @Sematext
A while ago we published this post where we explained how you can get stats about rsyslog, such as the number of messages enqueued, the number of output errors and so on. The point was to send them to Elasticsearch (or Logsene, our logging SaaS, which exposes the Elasticsearch API) in order to analyze them.
This is part 2 of that story, where we share how we process these stats in production. We’ll cover:
- an updated config, working with Elasticsearch 2.x
- what Kibana dashboards we have in Logsene to get an overview of what rsyslog is doing
- how we send some of these metrics to SPM as well, in order to set up alerts on their values: both threshold-based alerts and anomaly detection
Continue reading “Monitoring rsyslog’s impstats with Kibana and SPM”
rsyslog 8.16.0 (v8-stable) released
We have released rsyslog 8.16.0.
This release is mostly a bugfixing release with fixes for impstats, omelasticsearch, imfile, ommail and many more. The biggest change however is the addition of the extraction support in rsgtutil for ksi support (https://github.com/rsyslog/rsyslog/issues/561).
http://www.rsyslog.com/changelog-for-8-16-0-v8-stable/
Download:
http://www.rsyslog.com/downloads/download-v8-stable/
As always, feedback is appreciated.
Best regards,
Florian Riedl
Changelog for 8.16.0 (v8-stable)
——————————————————————————
Version 8.16.0 [v8-stable] 2016-01-26
- rsgtutil: Added extraction support including loglines and hash chains.
More details on how to extract loglines can be found in the rsgtutil
manpage. See also: https://github.com/rsyslog/rsyslog/issues/561 - clean up doAction output module interface
We started with char * pointers, but used different types of pointers
over time. This lead to alignment warnings. In practice, I think this
should never cause any problems (at least there have been no reports
in the 7 or so years we do this), but it is not clean. The interface is
now cleaned up. We do this in a way that does not require modifications
to modules that just use string parameters. For those with message
parameters, have a look at e.g. mmutf8fix to see how easy the
required change is. - new system properties for $NOW properties based on UTC
This permits to express current system time in UTC.
See also https://github.com/rsyslog/rsyslog/issues/729 - impstats: support broken ElasticSearch JSON implementation
ES 2.0 no longer supports valid JSON and disallows dots inside names.
This adds a new “json-elasticsearch” format option which replaces
those dots by the bang (“!”) character. So “discarded.full” becomes
“discarded!full”.
This is a workaroud. A method that will provide more control over
replacements will be implemented some time in the future. For
details, see below-quoted issue tracker.
closes https://github.com/rsyslog/rsyslog/issues/713 - omelasticsearch: craft better URLs
Elasticsearch is confused by url’s ending in a bare ‘?’ or ‘&’. While
this is valid, those are no longer produced.
Thanks to Benno Evers for the patch. - imfile: add experimental “reopenOnTruncate” parameter
Thanks to Matthew Wang for the patch. - bugfix imfile: proper handling of inotify initialization failure
Thanks to Zachary Zhao for the patch. - bugfix imfile: potential segfault due to improper handling of ev var
This occurs in inotify mode, only.
Thanks to Zachary Zhao and Peter Portante for the patch.
closes https://github.com/rsyslog/rsyslog/issues/718 - bugfix imfile: potential segfault under heavey load.
This occurs in inotify mode when using wildcards, only.
The root cause is dropped IN_IGNOPRED inotify events which be dropped
in circumstance of high input pressure and frequent rotation, and
according to wikipeida, they can also be dropped in other conditions.
Thanks to Zachary Zhao for the patch.
closes https://github.com/rsyslog/rsyslog/issues/723 - bugfix ommail: invalid handling of server response
if that response was split into different read calls. Could lead to
error-termination of send operation. Problem is pretty unlikely to
occur in standard setups (requires slow connection to SMTP server).
Thank to github user haixingood for the patch. - bugfix omelasticsearch: custom serverport was ignored on some platforms
Thanks to Benno Evers for the patch. - bugfix: tarball did not include some testbench files
Thanks to Thomas D. (whissi) for the patch. - bugfix: memory misadressing during config parsing string template
This occurred if an (invalid) template option larger than 63 characters
was given.
Thanks to git hub user c6226 for the patch. - bugfix imzmq: memory leak
Thanks to Jeremy Liang for the patch. - bugfix imzmq: memory leak
Thanks to github user xushengping for the patch. - bugfix omzmq: memory leak
Thanks to Jack Lin for the patch. - some code improvement and cleanup
rsyslog 8.15.0 (v8-stable) released
We have released rsyslog 8.15.0.
This release sports a lot of changes. Among the changes are a lot of bugfixes, changes to the KSI support, pmciscoios, omkafka, 0mq modules, omelasticsearch and many more.
http://www.rsyslog.com/changelog-for-8-15-0-v8-stable/
Download:
http://www.rsyslog.com/downloads/download-v8-stable/
As always, feedback is appreciated.
Best regards,
Florian Riedl
Recipe: Apache Logs + rsyslog (parsing) + Elasticsearch
Original post: Recipe: Apache Logs + rsyslog (parsing) + Elasticsearch by @Sematext
This recipe is about tailing Apache HTTPD logs with rsyslog, parsing them into structured JSON documents, and forwarding them to Elasticsearch (or a log analytics SaaS, like Logsene, which exposes the Elasticsearch API). Having them indexed in a structured way will allow you to do better analytics with tools like Kibana:

We’ll also cover pushing logs coming from the syslog socket and kernel, and how to buffer all of them properly. So this is quite a complete recipe for your centralized logging needs.
Getting the ingredients
Even though most distros already have rsyslog installed, it’s highly recommended to get the latest stable from the rsyslog repositories. The packages you’ll need are:
- rsyslog. The base package, including the file-tailing module (imfile)
- rsyslog-mmnormalize. This gives you mmnormalize, a module that will do the parsing of common Apache logs to JSON
- rsyslog-elasticsearch, for the Elasticsearch output
With the ingredients in place, let’s start cooking a configuration. The configuration needs to do the following:
- load the required modules
- configure inputs: tailing Apache logs and system logs
- configure the main queue to buffer your messages. This is also the place to define the number of worker threads and batch sizes (which will also be Elasticsearch bulk sizes)
- parse common Apache logs into JSON
- define a template where you’d specify how JSON messages would look like. You’d use this template to send logs to Logsene/Elasticsearch via the Elasticsearch output
Loading modules
Here, we’ll need imfile to tail files, mmnormalize to parse them, and omelasticsearch to send them. If you want to tail the system logs, you’d also need to include imuxsock and imklog (for kernel logs).
# system logs module(load="imuxsock") module(load="imklog") # file module(load="imfile") # parser module(load="mmnormalize") # sender module(load="omelasticsearch")
Configure inputs
For system logs, you typically don’t need any special configuration (unless you want to listen to a non-default Unix Socket). For Apache logs, you’d point to the file(s) you want to monitor. You can use wildcards for file names as well. You also need to specify a syslog tag for each input. You can use this tag later for filtering.
input(type="imfile"
File="/var/log/apache*.log"
Tag="apache:"
)NOTE: By default, rsyslog will not poll for file changes every N seconds. Instead, it will rely on the kernel (via inotify) to poke it when files get changed. This makes the process quite realtime and scales well, especially if you have many files changing rarely. Inotify is also less prone to bugs when it comes to file rotation and other events that would otherwise happen between two “polls”. You can still use the legacy mode=”polling” by specifying it in imfile’s module parameters.
Queue and workers
By default, all incoming messages go into a main queue. You can also separate flows (e.g. files and system logs) by using different rulesets but let’s keep it simple for now.
For tailing files, this kind of queue would work well:
main_queue( queue.workerThreads="4" queue.dequeueBatchSize="1000" queue.size="10000" )
This would be a small in-memory queue of 10K messages, which works well if Elasticsearch goes down, because the data is still in the file and rsyslog can stop tailing when the queue becomes full, and then resume tailing. 4 worker threads will pick batches of up to 1000 messages from the queue, parse them (see below) and send the resulting JSONs to Elasticsearch.
If you need a larger queue (e.g. if you have lots of system logs and want to make sure they’re not lost), I would recommend using a disk-assisted memory queue, that will spill to disk whenever it uses too much memory:
main_queue( queue.workerThreads="4" queue.dequeueBatchSize="1000" queue.highWatermark="500000" # max no. of events to hold in memory queue.lowWatermark="200000" # use memory queue again, when it's back to this level queue.spoolDirectory="/var/run/rsyslog/queues" # where to write on disk queue.fileName="stats_ruleset" queue.maxDiskSpace="5g" # it will stop at this much disk space queue.size="5000000" # or this many messages queue.saveOnShutdown="on" # save memory queue contents to disk when rsyslog is exiting )
Parsing with mmnormalize
The message normalization module uses liblognorm to do the parsing. So in the configuration you’d simply point rsyslog to the liblognorm rulebase:
action(type="mmnormalize" rulebase="/opt/rsyslog/apache.rb" )
where apache.rb will contain rules for parsing apache logs, that can look like this:
version=2 rule=:%clientip:word% %ident:word% %auth:word% [%timestamp:char-to:]%] "%verb:word% %request:word% HTTP/%httpversion:float%" %response:number% %bytes:number% "%referrer:char-to:"%" "%agent:char-to:"%"%blob:rest%
Where version=2 indicates that rsyslog should use liblognorm’s v2 engine (which is was introduced in rsyslog 8.13) and then you have the actual rule for parsing logs. You can find more details about configuring those rules in the liblognorm documentation.
Besides parsing Apache logs, creating new rules typically requires a lot of trial and error. To check your rules without messing with rsyslog, you can use the lognormalizer binary like:
head -1 /path/to/log.file | /usr/lib/lognorm/lognormalizer -r /path/to/rulebase.rb -e json
NOTE: If you’re used to Logstash’s grok, this kind of parsing rules will look very familiar. However, things are quite different under the hood. Grok is a nice abstraction over regular expressions, while liblognorm builds parse trees out of specialized parsers. This makes liblognorm much faster, especially as you add more rules. In fact, it scales so well, that for all practical purposes, performance depends on the length of the log lines and not on the number of rules. This post explains the theory behind this assuption, and this is actually proven by various tests. The downside is that you’ll lose some of the flexibility offered by regular expressions. You can still use regular expressions with liblognorm (you’d need to set allow_regex to on when loading mmnormalize) but then you’d lose a lot of the benefits that come with the parse tree approach.
Template for parsed logs
Since we want to push logs to Elasticsearch as JSON, we’d need to use templates to format them. For Apache logs, by the time parsing ended, you already have all the relevant fields in the $!all-json variable, that you’ll use as a template:
template(name="all-json" type="list"){
property(name="$!all-json")
}Template for time-based indices
For the logging use-case, you’d probably want to use time-based indices (e.g. if you keep your logs for 7 days, you can have one index per day). Such a design will give your cluster a lot more capacity due to the way Elasticsearch merges data in the background (you can learn the details in our presentations at GeeCON and Berlin Buzzwords).
To make rsyslog use daily or other time-based indices, you need to define a template that builds an index name off the timestamp of each log. This is one that names them logstash-YYYY.MM.DD, like Logstash does by default:
template(name="logstash-index"
type="list") {
constant(value="logstash-")
property(name="timereported" dateFormat="rfc3339" position.from="1" position.to="4")
constant(value=".")
property(name="timereported" dateFormat="rfc3339" position.from="6" position.to="7")
constant(value=".")
property(name="timereported" dateFormat="rfc3339" position.from="9" position.to="10")
}And then you’d use this template in the Elasticsearch output:
action(type="omelasticsearch" template="all-json" dynSearchIndex="on" searchIndex="logstash-index" searchType="apache" server="MY-ELASTICSEARCH-SERVER" bulkmode="on" action.resumeretrycount="-1" )
Putting both Apache and system logs together
If you use the same rsyslog to parse system logs, mmnormalize won’t parse them (because they don’t match Apache’s common log format). In this case, you’ll need to pick the rsyslog properties you want and build an additional JSON template:
template(name="plain-syslog"
type="list") {
constant(value="{")
constant(value="\"timestamp\":\"") property(name="timereported" dateFormat="rfc3339")
constant(value="\",\"host\":\"") property(name="hostname")
constant(value="\",\"severity\":\"") property(name="syslogseverity-text")
constant(value="\",\"facility\":\"") property(name="syslogfacility-text")
constant(value="\",\"tag\":\"") property(name="syslogtag" format="json")
constant(value="\",\"message\":\"") property(name="msg" format="json")
constant(value="\"}")
}Then you can make rsyslog decide: if a log was parsed successfully, use the all-json template. If not, use the plain-syslog one:
if $parsesuccess == "OK" then {
action(type="omelasticsearch"
template="all-json"
...
)
} else {
action(type="omelasticsearch"
template="plain-syslog"
...
)
}And that’s it! Now you can restart rsyslog and get both your system and Apache logs parsed, buffered and indexed into Elasticsearch. If you’re a Logsene user, the recipe is a bit simpler: you’d follow the same steps, except that you’ll skip the logstash-index template (Logsene does that for you) and your Elasticsearch actions will look like this:
action(type="omelasticsearch" template="all-json or plain-syslog" searchIndex="LOGSENE-APP-TOKEN-GOES-HERE" searchType="apache" server="logsene-receiver.sematext.com" serverport="80" bulkmode="on" action.resumeretrycount="-1" )
Coupling with Logstash via Redis
Original post: Recipe: rsyslog + Redis + Logstash by @Sematext
OK, so you want to hook up rsyslog with Logstash. If you don’t remember why you want that, let me give you a few hints:
- Logstash can do lots of things, it’s easy to set up but tends to be too heavy to put on every server
- you have Redis already installed so you can use it as a centralized queue. If you don’t have it yet, it’s worth a try because it’s very light for this kind of workload.
- you have rsyslog on pretty much all your Linux boxes. It’s light and surprisingly capable, so why not make it push to Redis in order to hook it up with Logstash?
In this post, you’ll see how to install and configure the needed components so you can send your local syslog (or tail files with rsyslog) to be buffered in Redis so you can use Logstash to ship them to Elasticsearch, a logging SaaS like Logsene (which exposes the Elasticsearch API for both indexing and searching) so you can search and analyze them with Kibana:
