Using rsyslog to Reindex/Migrate Elasticsearch data
Original post: Scalable and Flexible Elasticsearch Reindexing via rsyslog by @Sematext
This recipe is useful in a two scenarios:
- migrating data from one Elasticsearch cluster to another (e.g. when you’re upgrading from Elasticsearch 1.x to 2.x or later)
- reindexing data from one index to another in a cluster pre 2.3. For clusters on version 2.3 or later, you can use the Reindex API
Back to the recipe, we used an external application to scroll through Elasticsearch documents in the source cluster and push them to rsyslog via TCP. Then we used rsyslog’s Elasticsearch output to push logs to the destination cluster. The overall flow would be:
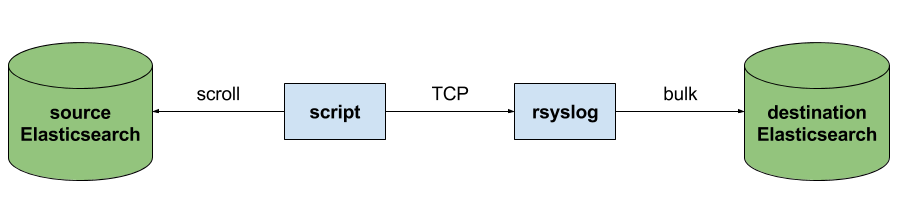
This is an easy way to extend rsyslog, using whichever language you’re comfortable with, to support more inputs. Here, we piggyback on the TCP input. You can do a similar job with filters/parsers – you can find GeoIP implementations, for example – by piggybacking the mmexternal module, which uses stdout&stdin for communication. The same is possible for outputs, normally added via the omprog module: we did this to add a Solr output and one for SPM custom metrics.
The custom script in question doesn’t have to be multi-threaded, you can simply spin up more of them, scrolling different indices. In this particular case, using two scripts gave us slightly better throughput, saturating the network:
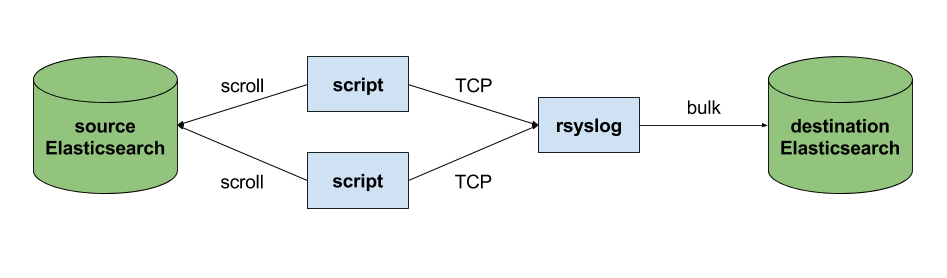
Writing the custom script
Before starting to write the script, one needs to know how the messages sent to rsyslog would look like. To be able to index data, rsyslog will need an index name, a type name and optionally an ID. In this particular case, we were dealing with logs, so the ID wasn’t necessary.
With this in mind, I see a number of ways of sending data to rsyslog:
- one big JSON per line. One can use mmnormalize to parse that JSON, which then allows rsyslog do use values from within it as index name, type name, and so on
- for each line, begin with the bits of “extra data” (like index and type names) then put the JSON document that you want to reindex. Again, you can use mmnormalize to parse, but this time you can simply trust that the last thing is a JSON and send it to Elasticsearch directly, without the need to parse it
- if you only need to pass two variables (index and type name, in this case), you can piggyback on the vague spec of RFC3164 syslog and send something like
destination_index document_type:{"original": "document"}
This last option will parse the provided index name in the hostname variable, the type in syslogtag and the original document in msg. A bit hacky, I know, but quite convenient (makes the rsyslog configuration straightforward) and very fast, since we know the RFC3164 parser is very quick and it runs on all messages anyway. No need for mmnormalize, unless you want to change the document in-flight with rsyslog.
Below you can find the Python code that can scan through existing documents in an index (or index pattern, like logstash_2016.05.*) and push them to rsyslog via TCP. You’ll need the Python Elasticsearch client (pip install elasticsearch) and you’d run it like this:
python elasticsearch_to_rsyslog.py source_index destination_index
The script being:
from elasticsearch import Elasticsearch
import json, socket, sys
source_cluster = ['server1', 'server2']
rsyslog_address = '127.0.0.1'
rsyslog_port = 5514
es = Elasticsearch(source_cluster,
retry_on_timeout=True,
max_retries=10)
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((rsyslog_address, rsyslog_port))
result = es.search(index=sys.argv[1], scroll='1m', search_type='scan', size=500)
while True:
res = es.scroll(scroll_id=result['_scroll_id'], scroll='1m')
for hit in result['hits']['hits']:
s.send(sys.argv[2] + ' ' + hit["_type"] + ':' + json.dumps(hit["_source"])+'\n')
if not result['hits']['hits']:
break
s.close()
If you need to modify messages, you can parse them in rsyslog via mmjsonparse and then add/remove fields though rsyslog’s scripting language. Though I couldn’t find a nice way to change field names – for example to remove the dots that are forbidden since Elasticsearch 2.0 – so I did that in the Python script:
def de_dot(my_dict):
for key, value in my_dict.iteritems():
if '.' in key:
my_dict[key.replace('.','_')] = my_dict.pop(key)
if type(value) is dict:
my_dict[key] = de_dot(my_dict.pop(key))
return my_dict
And then the “send” line becomes:
s.send(sys.argv[2] + ' ' + hit["_type"] + ':' + json.dumps(de_dot(hit["_source"]))+'\n')
Configuring rsyslog
The first step here is to make sure you have the lastest rsyslog, though the config below works with versions all the way back to 7.x (which can be found in most Linux distributions). You just need to make sure the rsyslog-elasticsearch package is installed, because we need the Elasticsearch output module.
# messages bigger than this are truncated
$maxMessageSize 10000000 # ~10MB
# load the TCP input and the ES output modules
module(load="imtcp")
module(load="omelasticsearch")
main_queue(
# buffer up to 1M messages in memory
queue.size="1000000"
# these threads process messages and send them to Elasticsearch
queue.workerThreads="4"
# rsyslog processes messages in batches to avoid queue contention
# this will also be the Elasticsearch bulk size
queue.dequeueBatchSize="4000"
)
# we use templates to specify how the data sent to Elasticsearch looks like
template(name="document" type="list"){
# the "msg" variable contains the document
property(name="msg")
}
template(name="index" type="list"){
# "hostname" has the index name
property(name="hostname")
}
template(name="type" type="list"){
# "syslogtag" has the type name
property(name="syslogtag")
}
# start the TCP listener on the port we pointed the Python script to
input(type="imtcp" port="5514")
# sending data to Elasticsearch, using the templates defined earlier
action(type="omelasticsearch"
template="document"
dynSearchIndex="on" searchIndex="index"
dynSearchType="on" searchType="type"
server="localhost" # destination Elasticsearch host
serverport="9200" # and port
bulkmode="on" # use the bulk API
action.resumeretrycount="-1" # retry indefinitely if Elasticsearch is unreachable
)
This configuration doesn’t have to disturb your local syslog (i.e. by replacing /etc/rsyslog.conf). You can put it someplace else and run a different rsyslog process:
rsyslogd -i /var/run/rsyslog_reindexer.pid -f /home/me/rsyslog_reindexer.conf
And that’s it! With rsyslog started, you can start the Python script(s) and do the reindexing.