rsyslog 8.21.0 (v8-stable) released
We have released rsyslog 8.21.0.
This release is mostly for maintenance. There was a big change to how internal messages are handled. These are no longer logged via the internal bridge, but via the syslog() API call. For regular users, this should make not too much difference.
Additionaly, the TLS syslog error messages have been improved, as well as the robustness of the queue subsystem.
https://github.com/rsyslog/rsyslog/blob/v8-stable/ChangeLog
Download:
http://www.rsyslog.com/downloads/download-v8-stable/
As always, feedback is appreciated.
Best regards,
Florian Riedl
Monitoring rsyslog’s impstats with Kibana and SPM
Original post: Monitoring rsyslog with Kibana and SPM by @Sematext
A while ago we published this post where we explained how you can get stats about rsyslog, such as the number of messages enqueued, the number of output errors and so on. The point was to send them to Elasticsearch (or Logsene, our logging SaaS, which exposes the Elasticsearch API) in order to analyze them.
This is part 2 of that story, where we share how we process these stats in production. We’ll cover:
- an updated config, working with Elasticsearch 2.x
- what Kibana dashboards we have in Logsene to get an overview of what rsyslog is doing
- how we send some of these metrics to SPM as well, in order to set up alerts on their values: both threshold-based alerts and anomaly detection
Continue reading “Monitoring rsyslog’s impstats with Kibana and SPM”
RSyslog Windows Agent 3.2 Released
Adiscon is proud to announce the 3.2 release of RSyslog Windows Agent.
This is a maintenenance release for RSyslog Windows Agent, which includes Features and bugfixes.
There is a huge list of changes, but the most important is the enhanced support for file based configurations.
Also inbuild components like OpenSSL and NetSNMP have been updated to the latest versions.
Detailed information can be found in the version history below.
Build-IDs: Service 3.2.143, Client 3.2.0.230
Features |
|
Bugfixes |
|
Version 3.2 is a free download. Customers with existing 2.x keys can contact our Sales department for upgrade prices. If you have a valid Upgrade Insurance ID, you can request a free new key by sending your Upgrade Insurance ID to sales@adiscon.com. Please note that the download enables the free 30-day trial version if used without a key – so you can right now go ahead and evaluate it.
Changelog for 8.17.0 (v8-stable)
Version 8.17.0 [v8-stable] 2016-03-08
- NEW REQUIREMENT: libfastjson
see also:
http://blog.gerhards.net/2015/12/rsyslog-and-liblognorm-will-switch-to.html - new testbench requirement: faketime command line tool
This is used to generate a controlled environment for time-based tests; if
not available, tests will gracefully be skipped. - improve json variable performance
We use libfastjson’s alternative hash function, which has been
proven to be much faster than the default one (which stems
back to libjson-c). This should bring an overall performance
improvement for all operations involving variable processing.
closes https://github.com/rsyslog/rsyslog/issues/848 - new experimental feature: lookup table suport
Note that at this time, this is an experimental feature which is not yet
fully supported by the rsyslog team. It is introduced in order to gain
more feedback and to make it available as early as possible because many
people consider it useful.
Thanks to Janmejay Singh for implementing this feature - new feature: dynamic statistics counters
which may be changed during rule processing
Thanks to Janmejay Singh for suggesting and implementing this feature - new contributed plugin: omampq1 for AMQP 1.0-compliant brokers
Thanks to Ken Giusti for this module - new set of UTC-based $now family of variables ($now-utc, $year-utc, …)
- simplified locking when accessing message and local variables
this simlifies the code and slightly increases performance if such
variables are heavily accessed. - new global parameter “debug.unloadModules”
This permits to disable unloading of modules, e.g. to make valgrind
reports more useful (without a need to recompile). - timestamp handling: guard against invalid dates
We do not permit dates outside of the year 1970..2100
interval. Note that network-receivers do already guard
against this, so the new guard only guards against invalid
system time. - imfile: add “trimlineoverbytes” input paramter
Thanks to github user JindongChen for the patch. - ommongodb: add support for extended json format for dates
Thanks to Florian Bücklers for the patch. - omjournal: add support for templates
see also: https://github.com/rsyslog/rsyslog/pull/770
Thanks to github user bobthemighty for the patch - imuxsock: add “ruleset” input parameter
- testbench: framework improvement: configs can be included in test file
they do no longer need to be in a separate file, which saves a bit
of work when working with them. This is supported for simple tests with
a single running rsyslog instance
Thanks to Janmejay Singh for inspiring me with a similar method in
liblognorm testbench. - imptcp: performance improvements
Thanks to Janmejay Singh for implementing this improvement - made build compile (almost) without warnings
still some warnings are suppressed where this is currently required - improve interface definition in some modules, e.g. mmanon, mmsequence
This is more an internal cleanup and should have no actual affect to
the end user. - solaris build: MAXHOSTNAMELEN properly detected
- build system improvement: ability to detect old hiredis libs
This permits to automatically build omhiredis on systems where the
hiredis libs do not provide a pkgconfig file. Previsouly, this
required manual configuration.
Thanks to github user jaymell for the patch. - rsgtutil: dump mode improvements
- auto-detect signature file type
- ability to dump hash chains for log extraction files
- build system: fix build issues with clang
clang builds often failed with a missing external symbol
“rpl_malloc”. This was caused by checks in configure.ac,
which checked for specific GNU semantics. As we do not need
them (we never ask malloc for zero bytes), we can safely
remove the macros.
Note that we routinely run clang static analyer in CI and
it also detects such calls as invalid.
closes https://github.com/rsyslog/rsyslog/issues/834 - bugfix: unixtimestamp date format was incorrectly computed
The problem happened in leap year from March til then end
of year and healed itself at the begining of the next year.
During the problem period, the timestamp was 24 hours too low.
fixes https://github.com/rsyslog/rsyslog/issues/830 - bugfix: date-ordinal date format was incorrectly computed
same root cause aus for unixtimestamp and same triggering
condition. During the affected perido, the ordinal was one
too less. - bugfix: some race when shutting down input module threads
this had little, if at all, effect on real deployments as it resulted
in a small leak right before rsyslog termination. However, it caused
trouble with the testbench (and other QA tools).
Thanks to Peter Portante for the patch and both Peter and Janmejay
Singh for helping to analyze what was going on. - bugfix tcpflood: did not handle connection drops correct in TLS case
note that tcpflood is a testbench too. The bug caused some testbench
instability, but had no effect on deplyments. - bugfix: abort if global parameter value was wrong
If so, the abort happened during startup. Once started,
all was stable. - bugfix omkafka: fix potential NULL pointer addressing
this happened when the topic cache was full and an entry
needed to be evicted - bugfix impstats: @cee cookie was prefixed to wrong fromat (json vs. cee)
Thanks to Volker Fröhlich for the fix. - bugfix imfile: fix race during startup that could lead to some duplication
If a to-be-monitored file was created after inotify was initialized
but before startup was completed, the first chunk of data from this
file could be duplicated. This should have happened very rarely in
practice, but caused occasional testbench failures.
see also: https://github.com/rsyslog/rsyslog/issues/791 - bugfix: potential loss of single message at queue shutdown
see also: https://github.com/rsyslog/rsyslog/issues/262 - bugfix: potential deadlock with heavy variable access
When making havy use of global, local and message variables, a deadlock
could occur. While it is extremly unlikely to happen, we have at least
seen one incarnation of this problem in practice. - bugfix ommysql: on some platforms, serverport parameter had no effect
This was caused by an invalid code sequence which’s outcome depends on
compiler settings. - bugfix omelasticsearch: invalid pointer dereference
The actual practical impact is not clear. This came up when working
on compiler warnings.
Thanks to David Lang for the patch. - bugfix omhiredis: serverport config parameter did not reliably work
depended on environment/compiler used to build - bugfix rsgtutil: -h command line option did not work
Thanks to Henri Lakk for the patch. - bugfix lexer: hex numbers were not properly represented
see: https://github.com/rsyslog/rsyslog/pull/771
Thanks to Sam Hanes for the patch. - bugfix TLS syslog: intermittent errors while sending data
Regression from commit 1394e0b. A symptom often seen was the message
“unexpected GnuTLS error -50 in nsd_gtls.c:530” - bugfix imfile: abort on startup if no slash was present in file name param
Thanks to Brian Knox for the patch. - bugfix rsgtutil: fixed abort when using short command line options
Thanks to Henri Lakk - bugfix rsgtutil: invalid computation of log record extraction file
This caused verification to fail because the hash chain was actually
incorrect. Depended on the input data set.
closes https://github.com/rsyslog/rsyslog/issues/832 - bugfix build system: KSI components could only be build if in default path
Changelog for 8.16.0 (v8-stable)
——————————————————————————
Version 8.16.0 [v8-stable] 2016-01-26
- rsgtutil: Added extraction support including loglines and hash chains.
More details on how to extract loglines can be found in the rsgtutil
manpage. See also: https://github.com/rsyslog/rsyslog/issues/561 - clean up doAction output module interface
We started with char * pointers, but used different types of pointers
over time. This lead to alignment warnings. In practice, I think this
should never cause any problems (at least there have been no reports
in the 7 or so years we do this), but it is not clean. The interface is
now cleaned up. We do this in a way that does not require modifications
to modules that just use string parameters. For those with message
parameters, have a look at e.g. mmutf8fix to see how easy the
required change is. - new system properties for $NOW properties based on UTC
This permits to express current system time in UTC.
See also https://github.com/rsyslog/rsyslog/issues/729 - impstats: support broken ElasticSearch JSON implementation
ES 2.0 no longer supports valid JSON and disallows dots inside names.
This adds a new “json-elasticsearch” format option which replaces
those dots by the bang (“!”) character. So “discarded.full” becomes
“discarded!full”.
This is a workaroud. A method that will provide more control over
replacements will be implemented some time in the future. For
details, see below-quoted issue tracker.
closes https://github.com/rsyslog/rsyslog/issues/713 - omelasticsearch: craft better URLs
Elasticsearch is confused by url’s ending in a bare ‘?’ or ‘&’. While
this is valid, those are no longer produced.
Thanks to Benno Evers for the patch. - imfile: add experimental “reopenOnTruncate” parameter
Thanks to Matthew Wang for the patch. - bugfix imfile: proper handling of inotify initialization failure
Thanks to Zachary Zhao for the patch. - bugfix imfile: potential segfault due to improper handling of ev var
This occurs in inotify mode, only.
Thanks to Zachary Zhao and Peter Portante for the patch.
closes https://github.com/rsyslog/rsyslog/issues/718 - bugfix imfile: potential segfault under heavey load.
This occurs in inotify mode when using wildcards, only.
The root cause is dropped IN_IGNOPRED inotify events which be dropped
in circumstance of high input pressure and frequent rotation, and
according to wikipeida, they can also be dropped in other conditions.
Thanks to Zachary Zhao for the patch.
closes https://github.com/rsyslog/rsyslog/issues/723 - bugfix ommail: invalid handling of server response
if that response was split into different read calls. Could lead to
error-termination of send operation. Problem is pretty unlikely to
occur in standard setups (requires slow connection to SMTP server).
Thank to github user haixingood for the patch. - bugfix omelasticsearch: custom serverport was ignored on some platforms
Thanks to Benno Evers for the patch. - bugfix: tarball did not include some testbench files
Thanks to Thomas D. (whissi) for the patch. - bugfix: memory misadressing during config parsing string template
This occurred if an (invalid) template option larger than 63 characters
was given.
Thanks to git hub user c6226 for the patch. - bugfix imzmq: memory leak
Thanks to Jeremy Liang for the patch. - bugfix imzmq: memory leak
Thanks to github user xushengping for the patch. - bugfix omzmq: memory leak
Thanks to Jack Lin for the patch. - some code improvement and cleanup
Changelog for 8.15.0 (v8-stable)
——————————————————————————
Version 8.15.0 [v8-stable] 2015-12-15
- KSI Lib: Updated code to run with libksi 3.4.0.5
Also libksi 3.4.0.x is required to build rsyslog if ksi support
is enabled. New libpackages have been build as well. - KSI utilities: Added option to ser publication url.
Since libksi 3.4.0.x, there is no default publication url anymore.
The publication url has to be set using the –publications-server
Parameter, otherwise the ksi signature cannot be verified. UserID
and UserKey can also be set by parameter now.
Closes https://github.com/rsyslog/rsyslog/issues/581 - KSI Lib: Fixed wrong TLV container for KSI signatures from 0905 to 0906.
closes https://github.com/rsyslog/rsyslog/issues/587 - KSI/GT Lib: Fixed multiple issues found using static analyzer
- performance improvement for configs with heavy use of JSON variables
Depending on the config, this can be a very big gain in performance. - added pmpanngfw: contributed module for translating Palo Alto Networks logs.
see also: https://github.com/rsyslog/rsyslog/pull/573
Thanks to Luigi Mori for the contribution. - testbench: Changed valgrind option for imtcp-tls-basic-vg.sh
For details see: https://github.com/rsyslog/rsyslog/pull/569 - pmciscoios: support for asterisk before timestamp added
thanks to github user c0by for the patch
see also: https://github.com/rsyslog/rsyslog/pull/583 - solr external output plugin much enhanced
see also: https://github.com/rsyslog/rsyslog/pull/529
Thanks to Radu Gheorghe for the patch. - omrabbitmq: improvements
thanks to Luigi Mori for the patch
see also: https://github.com/rsyslog/rsyslog/pull/580 - add support for libfastjson (as a replacement for json-c)
- KSI utilities: somewhat improved error messages
Thanks to Henri Lakk for the patch.
see also: https://github.com/rsyslog/rsyslog/pull/588 - pmciscoios: support for some format variations
Thanks to github user c0by for the patch - support grok via new contributed module mmgrok
Thanks to 饶琛琳 (github user chenryn) for the contribution. - omkafka: new statistics counter “maxoutqsize”
Thanks to 饶琛琳 (github user chenryn) for the contribution. - improvments for 0mq modules:
- omczmq – suspend / Retry handling – the output plugin can now recover
from some error states due to issues with plugin startup or message sending - omczmq – refactored topic handling code for ZMQ_PUB output to be a little
more efficient - omczmq – added ability to set a timeout for sends
- omczmq – set topics can be in separate frame (default) or part of message
frame (configurable) - omcmzq – code cleanup
- imczmq – code cleanup
- imczmq – fixed a couple of cases where vars could be used uninitialized
- imczmq – ZMQ_ROUTER support
- imczmq – Fix small memory leak from not freeing sockets when done with them
- allow creation of on demand ephemeral CurveZMQ certs for encryption.
Clients may specify clientcertpath=”*” to indicate they want an on
demand generated cert.
Thanks to Brian Knox for the contributions.
- omczmq – suspend / Retry handling – the output plugin can now recover
- cleanup on code to unset a variable
under extreme cases (very, very unlikely), the old code could also lead
to errornous processing - omelasticsearch: build on FreeBSD
Thanks to github user c0by for the patch - pmciscoios: fix some small issues clang static analyzer detected
- testbench: many improvements and some new tests
note that there still is a number of tests which are somewhat racy - overall code improvements thanks to clang static analyzer
- gnutls fix: Added possible fix for gnutls issue #575
see also: https://github.com/rsyslog/rsyslog/issues/575
Thanks to Charles Southerland for the patch - bugfix omkafka: restore ability to build on all platforms
Undo commit aea09800643343ab8b6aa205b0f10a4be676643b
because that lead to build failures on various important platforms.
This means it currently is not possible to configure the location
of librdkafka, but that will affect far fewer people.
closes: https://github.com/rsyslog/rsyslog/issues/596 - bugfix omkafka: fix potentially negative partition number
Thanks to Tait Clarridge for providing a patch. - bugfix: solve potential race in creation of additional action workers
Under extreme circumstances, this could lead to segfault. Note that we
detected this problem thanks to ASAN address sanitzier in combination
with a very exterme testbench test. We do not think that this issue
was ever reported in practice. - bugfix: potential memory leak in config parsing
Thanks to github user linmujia for the patch - bugfix: small memory leak in loading template config
This happened when a plugin was used inside the template. Then, the
memory for the template name was never freed.
Thanks to github user xushengping for the fix. - bugfix: fix extra whitespace in property expansions
Address off-by-one issues introduced in f3bd7a2 resulting in extra
whitespace in property expansions
Thanks to Matthew Gabeler-Lee for the patch. - bugfix: mmfields leaked memory if very large messages were processed
detected by clang static analyzer - bugfix: mmfields could add garbagge data to field
this happened when very large fields were to be processed.
Thanks to Peter Portante for reporting this. - bugfix: omhttpfs now also compiles with older json-c lib
- bugfix: memory leak in (contributed) module omhttpfs
Thanks to git hub user c6226 for the patch. - bugfix: parameter mismatch in error message for wrap() function
- bugfix: parameter mismatch in error message for random() function
- bugfix: divide by zero if max() function was provided zero
- bugfix: invalid mutex handling in omfile async write mode
could lead to segfault, even though highly unlikely (caught by
testbench on a single platform) - bugfix: fix inconsistent number processing
Unfortunately, previous versions of the rule engine tried to
support oct and hex, but that wasn’t really the case.
Everything based on JSON was just dec-converted. As this was/is
the norm, we fix that inconsistency by always using dec.
Luckly, oct and hex support was never documented and could
probably only have been activated by constant numbers. - bugfix: timezone() object: fix NULL pointer dereference
This happened during startup when the offset or id parameter was not
given. Could lead to a segfault at startup.
Detected by clang static analyzer. - bugfix omfile: memory addressing error if very long outchannel name used
Thanks to github user c6226 for the patch.
Recipe: Apache Logs + rsyslog (parsing) + Elasticsearch
Original post: Recipe: Apache Logs + rsyslog (parsing) + Elasticsearch by @Sematext
This recipe is about tailing Apache HTTPD logs with rsyslog, parsing them into structured JSON documents, and forwarding them to Elasticsearch (or a log analytics SaaS, like Logsene, which exposes the Elasticsearch API). Having them indexed in a structured way will allow you to do better analytics with tools like Kibana:

We’ll also cover pushing logs coming from the syslog socket and kernel, and how to buffer all of them properly. So this is quite a complete recipe for your centralized logging needs.
Getting the ingredients
Even though most distros already have rsyslog installed, it’s highly recommended to get the latest stable from the rsyslog repositories. The packages you’ll need are:
- rsyslog. The base package, including the file-tailing module (imfile)
- rsyslog-mmnormalize. This gives you mmnormalize, a module that will do the parsing of common Apache logs to JSON
- rsyslog-elasticsearch, for the Elasticsearch output
With the ingredients in place, let’s start cooking a configuration. The configuration needs to do the following:
- load the required modules
- configure inputs: tailing Apache logs and system logs
- configure the main queue to buffer your messages. This is also the place to define the number of worker threads and batch sizes (which will also be Elasticsearch bulk sizes)
- parse common Apache logs into JSON
- define a template where you’d specify how JSON messages would look like. You’d use this template to send logs to Logsene/Elasticsearch via the Elasticsearch output
Loading modules
Here, we’ll need imfile to tail files, mmnormalize to parse them, and omelasticsearch to send them. If you want to tail the system logs, you’d also need to include imuxsock and imklog (for kernel logs).
# system logs module(load="imuxsock") module(load="imklog") # file module(load="imfile") # parser module(load="mmnormalize") # sender module(load="omelasticsearch")
Configure inputs
For system logs, you typically don’t need any special configuration (unless you want to listen to a non-default Unix Socket). For Apache logs, you’d point to the file(s) you want to monitor. You can use wildcards for file names as well. You also need to specify a syslog tag for each input. You can use this tag later for filtering.
input(type="imfile"
File="/var/log/apache*.log"
Tag="apache:"
)NOTE: By default, rsyslog will not poll for file changes every N seconds. Instead, it will rely on the kernel (via inotify) to poke it when files get changed. This makes the process quite realtime and scales well, especially if you have many files changing rarely. Inotify is also less prone to bugs when it comes to file rotation and other events that would otherwise happen between two “polls”. You can still use the legacy mode=”polling” by specifying it in imfile’s module parameters.
Queue and workers
By default, all incoming messages go into a main queue. You can also separate flows (e.g. files and system logs) by using different rulesets but let’s keep it simple for now.
For tailing files, this kind of queue would work well:
main_queue( queue.workerThreads="4" queue.dequeueBatchSize="1000" queue.size="10000" )
This would be a small in-memory queue of 10K messages, which works well if Elasticsearch goes down, because the data is still in the file and rsyslog can stop tailing when the queue becomes full, and then resume tailing. 4 worker threads will pick batches of up to 1000 messages from the queue, parse them (see below) and send the resulting JSONs to Elasticsearch.
If you need a larger queue (e.g. if you have lots of system logs and want to make sure they’re not lost), I would recommend using a disk-assisted memory queue, that will spill to disk whenever it uses too much memory:
main_queue( queue.workerThreads="4" queue.dequeueBatchSize="1000" queue.highWatermark="500000" # max no. of events to hold in memory queue.lowWatermark="200000" # use memory queue again, when it's back to this level queue.spoolDirectory="/var/run/rsyslog/queues" # where to write on disk queue.fileName="stats_ruleset" queue.maxDiskSpace="5g" # it will stop at this much disk space queue.size="5000000" # or this many messages queue.saveOnShutdown="on" # save memory queue contents to disk when rsyslog is exiting )
Parsing with mmnormalize
The message normalization module uses liblognorm to do the parsing. So in the configuration you’d simply point rsyslog to the liblognorm rulebase:
action(type="mmnormalize" rulebase="/opt/rsyslog/apache.rb" )
where apache.rb will contain rules for parsing apache logs, that can look like this:
version=2 rule=:%clientip:word% %ident:word% %auth:word% [%timestamp:char-to:]%] "%verb:word% %request:word% HTTP/%httpversion:float%" %response:number% %bytes:number% "%referrer:char-to:"%" "%agent:char-to:"%"%blob:rest%
Where version=2 indicates that rsyslog should use liblognorm’s v2 engine (which is was introduced in rsyslog 8.13) and then you have the actual rule for parsing logs. You can find more details about configuring those rules in the liblognorm documentation.
Besides parsing Apache logs, creating new rules typically requires a lot of trial and error. To check your rules without messing with rsyslog, you can use the lognormalizer binary like:
head -1 /path/to/log.file | /usr/lib/lognorm/lognormalizer -r /path/to/rulebase.rb -e json
NOTE: If you’re used to Logstash’s grok, this kind of parsing rules will look very familiar. However, things are quite different under the hood. Grok is a nice abstraction over regular expressions, while liblognorm builds parse trees out of specialized parsers. This makes liblognorm much faster, especially as you add more rules. In fact, it scales so well, that for all practical purposes, performance depends on the length of the log lines and not on the number of rules. This post explains the theory behind this assuption, and this is actually proven by various tests. The downside is that you’ll lose some of the flexibility offered by regular expressions. You can still use regular expressions with liblognorm (you’d need to set allow_regex to on when loading mmnormalize) but then you’d lose a lot of the benefits that come with the parse tree approach.
Template for parsed logs
Since we want to push logs to Elasticsearch as JSON, we’d need to use templates to format them. For Apache logs, by the time parsing ended, you already have all the relevant fields in the $!all-json variable, that you’ll use as a template:
template(name="all-json" type="list"){
property(name="$!all-json")
}Template for time-based indices
For the logging use-case, you’d probably want to use time-based indices (e.g. if you keep your logs for 7 days, you can have one index per day). Such a design will give your cluster a lot more capacity due to the way Elasticsearch merges data in the background (you can learn the details in our presentations at GeeCON and Berlin Buzzwords).
To make rsyslog use daily or other time-based indices, you need to define a template that builds an index name off the timestamp of each log. This is one that names them logstash-YYYY.MM.DD, like Logstash does by default:
template(name="logstash-index"
type="list") {
constant(value="logstash-")
property(name="timereported" dateFormat="rfc3339" position.from="1" position.to="4")
constant(value=".")
property(name="timereported" dateFormat="rfc3339" position.from="6" position.to="7")
constant(value=".")
property(name="timereported" dateFormat="rfc3339" position.from="9" position.to="10")
}And then you’d use this template in the Elasticsearch output:
action(type="omelasticsearch" template="all-json" dynSearchIndex="on" searchIndex="logstash-index" searchType="apache" server="MY-ELASTICSEARCH-SERVER" bulkmode="on" action.resumeretrycount="-1" )
Putting both Apache and system logs together
If you use the same rsyslog to parse system logs, mmnormalize won’t parse them (because they don’t match Apache’s common log format). In this case, you’ll need to pick the rsyslog properties you want and build an additional JSON template:
template(name="plain-syslog"
type="list") {
constant(value="{")
constant(value="\"timestamp\":\"") property(name="timereported" dateFormat="rfc3339")
constant(value="\",\"host\":\"") property(name="hostname")
constant(value="\",\"severity\":\"") property(name="syslogseverity-text")
constant(value="\",\"facility\":\"") property(name="syslogfacility-text")
constant(value="\",\"tag\":\"") property(name="syslogtag" format="json")
constant(value="\",\"message\":\"") property(name="msg" format="json")
constant(value="\"}")
}Then you can make rsyslog decide: if a log was parsed successfully, use the all-json template. If not, use the plain-syslog one:
if $parsesuccess == "OK" then {
action(type="omelasticsearch"
template="all-json"
...
)
} else {
action(type="omelasticsearch"
template="plain-syslog"
...
)
}And that’s it! Now you can restart rsyslog and get both your system and Apache logs parsed, buffered and indexed into Elasticsearch. If you’re a Logsene user, the recipe is a bit simpler: you’d follow the same steps, except that you’ll skip the logstash-index template (Logsene does that for you) and your Elasticsearch actions will look like this:
action(type="omelasticsearch" template="all-json or plain-syslog" searchIndex="LOGSENE-APP-TOKEN-GOES-HERE" searchType="apache" server="logsene-receiver.sematext.com" serverport="80" bulkmode="on" action.resumeretrycount="-1" )
RSyslog Windows Agent 3.1 Released
Adiscon is proud to announce the 3.1 release of RSyslog Windows Agent.
This is a maintenenance release for RSyslog Windows Agent. It includes some bugfixes as well as a new rule date condition which can be used to process events starting from a certain date. A few new options have been added into the Syslog Service as well.
Detailed information can be found in the version history below.
Build-IDs: Service 3.1.0.134, Client 3.1.0.213
Features |
|
Bugfixes |
|
Version 3.1 is a free download. Customers with existing 2.x keys can contact our Sales department for upgrade prices. If you have a valid Upgrade Insurance ID, you can request a free new key by sending your Upgrade Insurance ID to sales@adiscon.com. Please note that the download enables the free 30-day trial version if used without a key – so you can right now go ahead and evaluate it.
Tutorial: Sending impstats Metrics to Elasticsearch Using Rulesets and Queues
Originally posted on the Sematext blog: Monitoring rsyslog’s Performance with impstats and Elasticsearch
If you’re using rsyslog for processing lots of logs (and, as we’ve shown before, rsyslog is good at processing lots of logs), you’re probably interested in monitoring it. To do that, you can use impstats, which comes from input module for process stats. impstats produces information like:
– input stats, like how many events went through each input
– queue stats, like the maximum size of a queue
– action (output or message modification) stats, like how many events were forwarded by each action
– general stats, like CPU time or memory usage
In this post, we’ll show you how to send those stats to Elasticsearch (or Logsene — essentially hosted ELK, our log analytics service, that exposes the Elasticsearch API), where you can explore them with a nice UI, like Kibana. For example get the number of logs going through each input/output per hour:
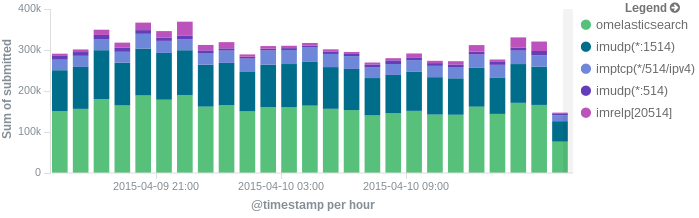
More precisely, we’ll look at:
– useful options around impstats
– how to use those stats and what they’re about
– how to ship stats to Elasticsearch/Logsene by using rsyslog’s Elasticsearch output
– how to do this shipping in a fast and reliable way. This will apply to most rsyslog use-cases, not only impstats
Continue reading “Tutorial: Sending impstats Metrics to Elasticsearch Using Rulesets and Queues”
Changelog for 8.9.0 (v8-stable)
Version 8.9.0 [v8-stable] 2015-04-07
- omprog: add option “hup.forward” to forwards HUP to external plugins
This was suggested by David Lang so that external plugins (and other
programs) can also do HUP-specific processing. The default is not
to forward HUP, so no change of behavior by default. - imuxsock: added capability to use regular parser chain
Previously, this was a fixed format, that was known to be spoken on
the system log socket. This also adds new parameters:- sysSock.useSpecialParser module parameter
- sysSock.parseHostname module parameter
- useSpecialParser input parameter
- parseHostname input parameter
- 0mq: improvements in input and output modules
See module READMEs, part is to be considered experimental.
Thanks to Brian Knox for the contribution. - imtcp: add support for ip based bind for imtcp -> param “address”
Thanks to github user crackytsi for the patch. - bugfix: MsgDeserialize out of sync with MsgSerialize for StrucData
This lead to failure of disk queue processing when structured data was
present. Thanks to github user adrush for the fix. - bugfix imfile: partial data loss, especially in readMode != 0
closes https://github.com/rsyslog/rsyslog/issues/144 - bugfix: potential large memory consumption with failed actions
see also https://github.com/rsyslog/rsyslog/issues/253 - bugfix: omudpspoof: invalid default send template in RainerScript format
The file format template was used, which obviously does not work for
forwarding. Thanks to Christopher Racky for alerting us.
closes https://github.com/rsyslog/rsyslog/issues/268 - bugfix: size-based legacy config statements did not work properly
on some platforms, they were incorrectly handled, resulting in all
sorts of “interesting” effects (up to segfault on startup) - build system: added option –without-valgrind-testbench
… which provides the capability to either enforce or turn off
valgrind use inside the testbench. Thanks to whissi for the patch. - rsyslogd: fix misleading typos in error messages
Thanks to Ansgar Püster for the fixes.