Tutorial: Sending impstats Metrics to Elasticsearch Using Rulesets and Queues
Originally posted on the Sematext blog: Monitoring rsyslog’s Performance with impstats and Elasticsearch
If you’re using rsyslog for processing lots of logs (and, as we’ve shown before, rsyslog is good at processing lots of logs), you’re probably interested in monitoring it. To do that, you can use impstats, which comes from input module for process stats. impstats produces information like:
– input stats, like how many events went through each input
– queue stats, like the maximum size of a queue
– action (output or message modification) stats, like how many events were forwarded by each action
– general stats, like CPU time or memory usage
In this post, we’ll show you how to send those stats to Elasticsearch (or Logsene — essentially hosted ELK, our log analytics service, that exposes the Elasticsearch API), where you can explore them with a nice UI, like Kibana. For example get the number of logs going through each input/output per hour:
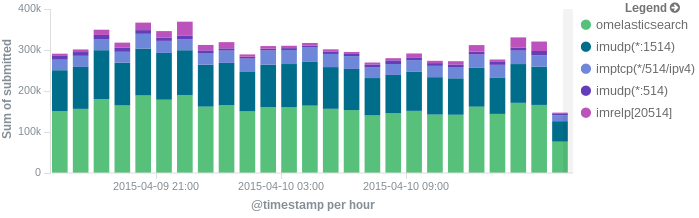
More precisely, we’ll look at:
– useful options around impstats
– how to use those stats and what they’re about
– how to ship stats to Elasticsearch/Logsene by using rsyslog’s Elasticsearch output
– how to do this shipping in a fast and reliable way. This will apply to most rsyslog use-cases, not only impstats
Continue reading “Tutorial: Sending impstats Metrics to Elasticsearch Using Rulesets and Queues”
Performance Tuning&Tests for the Elasticsearch Output
Original post: Rsyslog 8.1 Elasticsearch Output Performance by @Sematext
Version 8 brings major changes in rsyslog’s core – see Rainer’s presentation about it for more details. Those changes should give outputs better performance, and the Elasticsearch one should benefit a lot. Since we’re using rsyslog and Elasticsearch in Sematext‘s own log analytics product, Logsene, we had to take the new version for a spin.
The Weapon and the Target
For testing, we used a good-old i3 laptop, with 8GB of RAM. We generated 20 million logs, sent them to rsyslog via TCP and from there to Elasticsearch in the Logstash format, so they can get explored with Kibana. The objective was to stuff as many events per second into Elasticsearch as possible.
Rsyslog Architecture Overview
In order to tweak rsyslog effectively, one needs to understand its architecture, which is not that obvious (although there’s an ongoing effort to improve the documentation). The gist of it its architecture represented in the figure below.
- you have input modules taking messages (from files, TCP/UDP, journal, etc.) and pushing them to a main queue
- one or more main queue threads take those events and parse them. By default, they parse syslog formats (RFC-3164, RFC-5424 and various derivatives), but you can configure rsyslog to use message modifier modules to do additional parsing (e.g. CEE-formatted JSON messages). Either way, this parsing generates structured events, made out of properties
- after parsing, the main queue threads push events to the action queue. Or queues, if there are multiple actions and you want to fan-out
- for each defined action, one or more action queue threads takes properties from events according to templates, and makes messages that would be sent to the destination. In Elasticsearch’s case, a template should make Elasticsearch JSON documents, and the destination would be the REST API endpoint

There are two more things to say about rsyslog’s architecture before we move on to the actual test:
- you can have multiple independent flows (like the one in the figure above) in the same rsyslog process by using rulesets. Think of rulesets as swim-lanes. They’re useful for example when you want to process local logs and remote logs in a completely separate manner
- queues can be in-memory, on disk, or a combination called disk-assisted. Here, we’ll use in-memory because they’re the fastest. For more information about how queues work, take a look here
Configuration
To generate messages, we used tcpflood, a small and light tool that’s part of rsyslog’s testbench. It generates messages and sends them over to the local syslog via TCP.
Rsyslog took received those messages with the imtcp input module, queued them and forwarded them to Elasticsearch 0.90.7, which was also installed locally. We also tried with Elasticsearch 1.0 and got the same results (see below).
The flow of messages in this test is represented in the following figure:

The actual rsyslog config is listed below (in the new configuration format). It can be tuned further (for example by using the multithreaded imptcp input module), but we didn’t get significant improvements in this particular scenario.
module(load="imtcp") # TCP input module module(load="omelasticsearch") # Elasticsearch output module input(type="imtcp" port="13514") # where to listen for TCP messages main_queue( queue.size="1000000" # capacity of the main queue queue.dequeuebatchsize="1000" # process messages in batches of 1000 and move them to the action queues queue.workerthreads="2" # 2 threads for the main queue ) # template to generate JSON documents for Elasticsearch in Logstash format template(name="plain-syslog" type="list") { constant(value="{") constant(value="\"@timestamp\":\"") property(name="timereported" dateFormat="rfc3339") constant(value="\",\"host\":\"") property(name="hostname") constant(value="\",\"severity\":\"") property(name="syslogseverity-text") constant(value="\",\"facility\":\"") property(name="syslogfacility-text") constant(value="\",\"syslogtag\":\"") property(name="syslogtag" format="json") constant(value="\",\"message\":\"") property(name="msg" format="json") constant(value="\"}") } action(type="omelasticsearch" template="plain-syslog" # use the template defined earlier searchIndex="test-index" bulkmode="on" # use the Bulk API queue.dequeuebatchsize="5000" # ES bulk size queue.size="100000" # capacity of the action queue queue.workerthreads="5" # 5 workers for the action action.resumeretrycount="-1" # retry indefinitely if ES is unreachable )
You can see from the configuration that:
- both main and action queues have a defined size in number of messages
- both have number of threads that deliver messages to the next step. The action needs more because it has to wait for Elasticsearch to reply
- moving of messages from the queues happens in batches. For the Elasticsearch output, the batch of messages is sent through the Bulk API, which makes queue.dequeuebatchsize effectively the bulk size
Results
We started with default Elasticsearch settings. Then we tuned them to leave rsyslog with a more significant slice of the CPU. We monitored the indexing rate with SPM for Elasticsearch. Here are the average results over 20 million indexed events:
- with default Elasticsearch settings, we got 8,000 events per second
- after setting Elasticsearch up more production-like (5 second refresh interval, increased index buffer size, translog thresholds, etc), and the throughput went up to average of 20,000 events per second
- in the end, we went berserk and used in-memory indices, updated the mapping to disable any storing or indexing for any field, to have Elasticsearch do as little work as possible and make room for rsyslog. Got an average of 30,000 events per second. In this scenario, rsyslog was using between 1 and 1.5 of the 4 virtual CPU cores, with tcpflood using 0.5 and Elasticsearch using from 2 to 2.5
Conclusion
20K EPS on a low-end machine with production-like configuration means Elasticsearch is quick at indexing. This is very good for logs, where you typically have lots of messages being generated, compared to how often you search.
If you need some tool to ship your logs to Elasticsearch with minimum overhead, rsyslog version 8 may well be your best bet.
Related posts:
rsyslog 8.1.3 (v8-devel) released
We have just released 8.1.3 of the v8-devel branch.
Note that this release can be considered a “normal” devel version, with moderate risk associated to it. Experience in the past weeks suggest so. Special thanks to Pavel Levshin for all his work and tests. Still note that there is a considerably higher risk running the devel version than the stable one.
ChangeLog:
http://www.rsyslog.com/changelog-for-8-1-3-v8-devel/
Download:
http://www.rsyslog.com/rsyslog-8-1-3-v8-devel/
Feedback is *very much* appreciated.
Best regards,
Florian Riedl
Changelog for 8.1.3 (v8-devel)
Version 8.1.3 [devel] 2013-12-06
THIS VERSION CAN BE CONSIDERED A “NORMAL” DEVEL RELEASE. It’s no longer
highly experimental. This assertion is based on real-world feedback.
- changes to the strgen module interface
- new output module interface for transactional modules
- performance improvements
- reduced number of malloc/frees due to further changes to the output module interface
- reduced number of malloc/frees during string template processing
We now re-use once allocated string template memory for as long as the worker thread exists. This saves us from doing new memory allocs (and their free counterpart) when the next message is processed. The drawback is that the cache always is the size of the so-far largest message processed. This is not considered a problem, as in any case a single messages’ memory footprint should be far lower than that of a whole set of messages (especially on busy servers). - used variable qualifiers (const, __restrict__) to hopefully help the compiler generate somewhat faster code
- failed action detection more precisely for a number of actions
If an action uses string parameter passing but is non-transactional it can be executed immediately, giving a quicker indicatio of action failure. - bugfix: limiting queue disk space did not work properly
- queue.maxdiskspace actually initializes queue.maxfilesize
- total size of queue files was not checked against queue.maxdiskspace for disk assisted queues.
Thanks to Karol Jurak for the patch.
Main Advantages of rsyslog v7 vs. v5
Why rsyslog V7:
- greatly improved configuration language – the new language is much more intuitive than the legacy format. It will also prevent some typical mistakes simply by not permitting these invalid constructs. Note that legacy format is still fully supported (and you can of course do the same mistakes if you use legacy format).
- greatly improved execution engine – with nested if/then/else constructs as well as the capability to modify variables during processing.
- full support for structured logging and project lumberjack / CEE – this includes everything from being able to create, interpret and handle JSON-based structured log messages, including the ability to normalize legacy text log messages.
- more plugins – like support for MongoDB, HDFS, and ElasticSearch as well as for the kernel’s new structured logging system.
- higher performance – many optimizations all over the code, like 5 to 10 times faster execution time for script-based filters, enhanced multithreaded TCP input plugin, DNS cache and many more.
Of course, there are many more improvements. This list contains just the most important ones. For full details, check the file ChangeLog.