Using rsyslog and Elasticsearch to Handle Different Types of JSON Logs
Originally posted on the Sematext blog: Using Elasticsearch Mapping Types to Handle Different JSON Logs
By default, Elasticsearch does a good job of figuring the type of data in each field of your logs. But if you like your logs structured like we do, you probably want more control over how they’re indexed: is time_elapsed an integer or a float? Do you want your tags analyzed so you can search for big in big data? Or do you need it not_analyzed, so you can show top tags via the terms aggregation? Or maybe both?
In this post, we’ll look at how to use index templates to manage multiple types of logs across multiple indices. Also, we’ll explain how to use rsyslog to handle JSON logging and specify types.
Elasticsearch Mapping and Logs
To control settings for how a field is analyzed in Elasticsearch, you’ll need to define a mapping. This works similarly in Logsene, our log analytics SaaS, because it uses Elasticsearch and exposes its API.
With logs you’ll probably use time-based indices, because they scale better (in Logsene, for instance, you get daily indices). To make sure the mapping you define today applies to the index you create tomorrow, you need to define it in an index template.
Managing Multiple Types
Mappings provide a nice abstraction when you have to deal with multiple types of structured data. Let’s say you have two apps generating logs of different structures: both have a timestamp field, but one recording logins has a user field, and another one recording purchases has an amount field.
To deal with this, you can define the timestamp field in the _default_ mapping which applies to all types. Then, in each type’s own mapping we’ll define fields unique to that mapping. The following snippet is an example that works with Logsene, provided that aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee is your Logsene app token. If you roll your own Elasticsearch, you can use whichever name you want, and make sure the template name applies to matches index pattern (for example, logs-* will work if your indices are in the logs-YYYY-MM-dd format).
curl -XPUT 'logsene-receiver.sematext.com/_template/aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee_MyTemplate' -d '{
"template" : "aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee*",
"order" : 21,
"mappings" : {
"_default_" : {
"properties" : {
"timestamp" : { "type" : "date" }
}
},
"firstapp" : {
"properties" : {
"user" : { "type" : "string" }
}
},
"secondapp" : {
"properties" : {
"amount" : { "type" : "long" }
}
}
}
}'Sending JSON Logs to Specific Types
When you send a document to Elasticsearch by using the API, you have to provide an index and a type. You can use an Elasticsearch client for your preferred language to log directly to Elasticsearch or Logsene this way. But I wouldn’t recommend this, because then you’d have to manage things like buffering if the destination is unreachable.
Instead, I’d keep my logging simple and use a specialized logging tool, such as rsyslog, to do the hard work for me. Logging to a file is usually the easiest option. It’s local, and you can have your logging tool tail the file and send contents over the network. I usually prefer sockets (like syslog) because they let me configure rsyslog to:
– write events in a human format to a local file I can tail if I need to (usually in development)
– forward logs without hitting disk if I need to (usually in production)
Whatever you prefer, I think writing to local files or sockets is better than sending logs over the network from your application. Unless you’re willing to do a reliability trade-off and use UDP, which gets rid of most complexities.
Opinions aside, if you want to send JSON over syslog, there’s the JSON-over-syslog (CEE) format that we detailed in a previous post. You can use rsyslog’s JSON parser module to take your structured logs and forward them to Logsene:
module(load="imuxsock") # can listen to local syslog socket
module(load="omelasticsearch") # can forward to Elasticsearch
module(load="mmjsonparse") # can parse JSON
action(type="mmjsonparse") # parse CEE-formatted messages
template(name="syslog-cee" type="list") { # Elasticsearch documents will contain
property(name="$!all-json") # all JSON fields that were parsed
}
action(
type="omelasticsearch"
template="syslog-cee" # use the template defined earlier
server="logsene-receiver.sematext.com"
serverport="80"
searchType="syslogapp"
searchIndex="LOGSENE-APP-TOKEN-GOES-HERE"
bulkmode="on" # send logs in batches
queue.dequeuebatchsize="1000" # of up to 1000
action.resumeretrycount="-1" # retry indefinitely (buffer) if destination is unreachable
)To send a CEE-formatted syslog, you can run logger ‘@cee: {“amount”: 50}’ for example. Rsyslog would forward this JSON to Elasticsearch or Logsene via HTTP. Note that Logsene also supports CEE-formatted JSON over syslog out of the box if you want to use a syslog protocol instead of the Elasticsearch API.
Filtering by Type
Once your logs are in, you can filter them by type (via the _type field) in Kibana:

However, if you want more refined filtering by source, we suggest using a separate field for storing the application name. This can be useful when you have different applications using the same logging format. For example, both crond and postfix use plain syslog.
rsyslog 7.3.7 (v7-devel) released
We have just released v 7.3.7 of the rsyslog development branch. This release offers some important new features, most importantly a plugin to anonymize IPv4 addresses and a plugin to write to the systemd journal. Also, the field() RainerScript function has been upgraded to support multi-character field delimiters. There is also a number of bug fixes present.
ChangeLog:
http://www.rsyslog.com/changelog-for-7-3-7-v7-devel/
Download:
http://www.rsyslog.com/rsyslog-7-3-7-v7-devel/
As always, feedback is appreciated.
Best regards,
Florian Riedl
Changelog for 7.3.7 (v7-devel)
Version 7.3.7 [devel] 2013-03-12
- add support for anonymizing IPv4 addresses
- add support for writing to the Linux Journal (omjournal)
- imuxsock: add capability to ignore messages from ourselves
This helps prevent message routing loops, and is vital to have if omjournal is used together with traditional syslog. - field() function now supports a string as field delimiter
- added ability to configure debug system via rsyslog.conf
- bugfix: imuxsock segfault when system log socket was used
- bugfix: mmjsonparse segfault if new-style config was used
- bugfix: script == comparison did not work properly on JSON objects
- bugfix: field() function did never return “***FIELD NOT FOUND***”
instead it returned “***ERROR in field() FUNCTION***” in that case
Using MongoDB with rsyslog and LogAnalyzer
In this scenario we want to receive cee-formatted messages from a different system with rsyslog, store the messages with MongoDB and then display the stored messages with Adiscon LogAnalyzer. This is a very common use-case. Please read through the complete guide before starting.
We will split this guide in 3 main parts. These parts can consist of several steps.
- Setting up rsyslog
- Setting up MongoDB
- Setting up LogAnalyzer
This guide has been created with rsyslog 7.3.6 on ubuntu 12.04 LTS and Adiscon LogAnalyzer 3.6.3. All additional packages, services or applications where the latest version at that time.
Before you begin
Please note, there are many ways to distribute rsyslog. But, make sure that the platform you build rsyslog on is the same platform as where it should be used. You cannot build rsyslog on CentOS and use it on Ubuntu. The differences between the platforms are just to big. The same applies to different versions of the same platform. When building on a older platform and using it on a newer version, this may work, but with restrictions. Whereas building on a newer version and using it on a older version will probably not work at all. So, if you build rsyslog from Source and want to use it on another machine, make sure the platform is the same.
Step 1 – Setting up rsyslog
We need to setup rsyslog first. Not only do we need the core functionality, but several additional modules. For this case we want to receive the syslog messages via TCP, thus we need imtcp. For processing we need first mmjsonparse and ommongodb. Your configure should look like this.
./configure --prefix=/usr --enable-imtcp --enable-mmjsonparse --enable-ommongodb
The module mmjsonparse will be needed to verify and parse the @cee messages. Ommongodb will be used to write into the MongoDB. After the configure and installation, we can create our config. The config for our case looks like this:
module(load="imtcp") module(load="mmjsonparse") module(load="ommongodb")
input(type="imtcp" port="13514" Ruleset="mongodb")
template(name="mongodball" type="subtree" subtree="$!")
ruleset(name="mongodb") {
action(type="mmjsonparse")
if $parsesuccess == "OK" then {
set $!time = $timestamp;
set $!sys = $hostname;
set $!procid = $syslogtag;
set $!syslog_fac = $syslogfacility;
set $!syslog_sever = $syslogpriority;
set $!pid = $procid;
action(type="ommongodb" server="127.0.0.1" db="logs" collection="syslog" template="mongodball")
}
}As always, we first load the modules. The next part is the input. We need to receive tcp via imtcp. Please note, that we directly bind the input to a ruleset. The third part of the configuration is a template. We need it later when writing to MongoDB. Since we will automatically transform our @cee-message into json, we can use a subtree template. The template itself is basically the root of the subtree.
The last and most important part is the ruleset. Here all of our work is done. First, all messages are run through the mmjsonparse module. This will not only verify if we received a valid json message, but also transforms all the values into a json subtree. If the parsing was successful, we need to set several variables for the subtree. Information that is delivered in the syslog header will not be parsed into the subtree by mmjsonparse automatically. Thus we have to set subtree variables with the values of some default properties like timestamp, hostname and so on. After that we have basically all information from the complete syslog message in the subtree format. Finally a last action is needed. We need to write our log messages to MongoDB. In this example, MongoDB is installed on the same machine. We want to use the db “logs” and as collection we want to use “syslog”. And we use our subtree template to define the format that is written to MongoDB. Thus, all our parsed variables are stored separately. If we do not use this template, the @cee message gets written as it is into the msg field in MongoDB. But this is not what we want. We want all variables to be available separately.
That is basically it for rsyslog. You can now save the configuration and restart rsyslog. Though it won’t be able to be useful yet. We still need to install MongoDB.
Step 2 – Install MongoDB
Making a basic install for MongoDB is rather easy. Simply install the following packages:
mongodb mongodb-server php-pecl-mongo libmongo-client libglib2.0-dev
Please note, that package names may vary for different distributions.
After we have installed the packages, the MongoDB Server is already ready. By default, it is not secured by a user or password. Refer to the MongoDB manual for more information. Databases and collections (equivalent to tables) are created by rsyslog and do not need to be defined with the mongo shell. We will stick with the default setup to keep it simple.
Step 3 – Installing Adiscon LogAnalyzer
To run Adiscon LogAnalyzer, you need a webserver with PHP. The easiest way is to use apache2 and php5. To be able to access the MongoDB, we need to install an additional package. Run the following command
sudo pecl install mongo
You might need to install the package php-pear first, if it hasn’t been installed already with PHP.
After that, we need to put the following line into the file php.ini.
extension=mongo.so
Remember to restart your webserver after making changes to the php.ini. Without a lot of configuration, this should aready work.
We can now install Adiscon LogAnalyzer. Download the latest version from the Adiscon LogAnalyzer Download page and install it as it is described in the documentation.
The only difference we need to make is when setting up the log source in step 4.5. You need to set at least the following as shown in the screenshot:
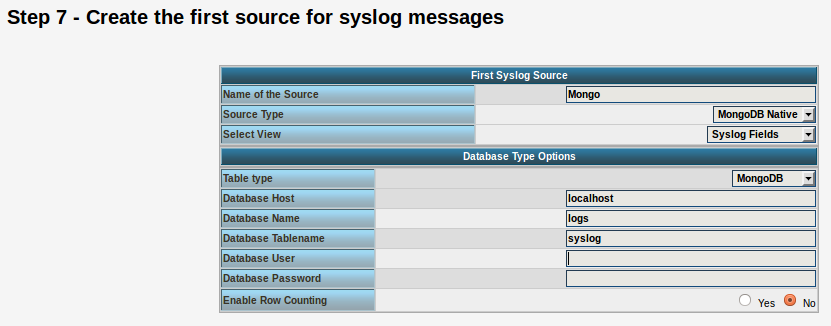
Source Type: MongoDB Native Table Type: MongoDB Database Name: logs Database Tablename: syslog Database user: <clear this field>
The User and Password is of course needed, if you set it in your MongoDB setup.
After you have finished the installation of Adiscon LogAnalyzer, you should now be seeing the LogAnalyzer overview and the log messages in a table view (if you have already stored them in MongoDB). Now if you click on a specific message, you get to see the detail view of the log message.
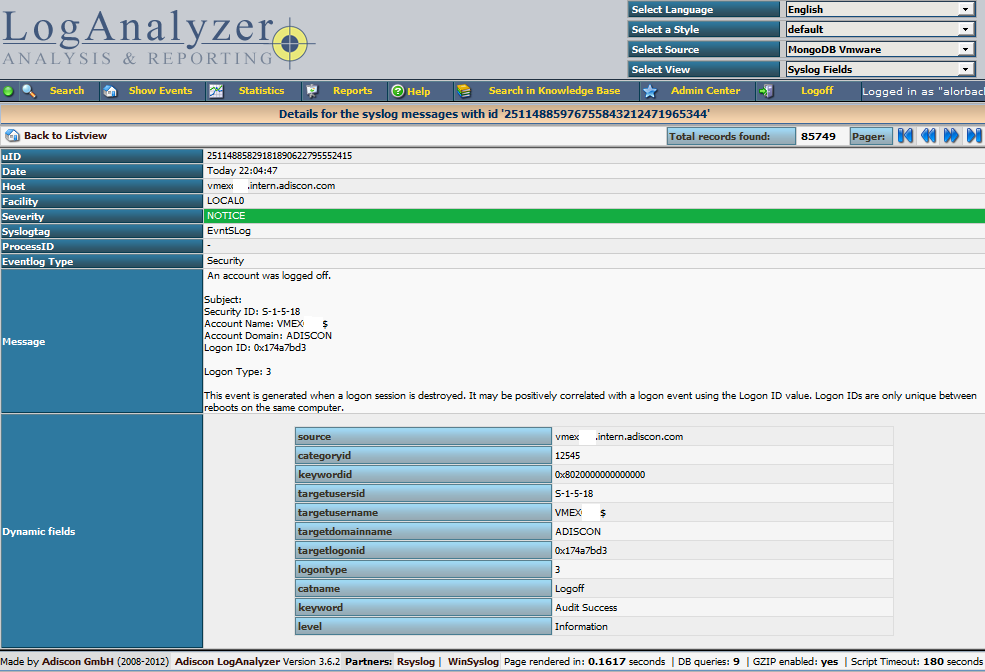
Click on the picture for a bigger size
As you can see, you get a list of dynamic fields. These fields where already sent in @cee format from the original source and were parsed by rsyslog and mmjsonparse and finally they were automatically filled into the MongoDB.
With this setup, you are independent of a fixed database structure. Fields are inserted dynamically into the database as they are available and they are dynamically display by Adiscon LogAnalyzer as well.
rsyslog 6.3.8 (v6-devel) released
This is an important new release of the rsyslog v6 devel branch. Among others, it is the version that supports many of the new things done for project lumberjack, better cee-enhanced syslog support as well as a much-improved mongodb driver. The release also contains numerous other enhancements as well as bug-fixes. Please note that part of the feature set is still experimental and unstable in a sense that interfaces or similar thing “taken for granted” (e.g. the default MongoDB schema) may change in later releases.
As a preliminary measure, please make sure you are using the most current versions of libee (0.4.1), libestr (0.1.2) and liblognorm (0.3.4).
ChangeLog:
http://www.rsyslog.com/changelog-for-6-3-8-v6-devel/
Download:
http://www.rsyslog.com/rsyslog-6-3-8-v6-devel/
As always, feedback is appreciated.
Best regards,
Florian Riedl
Changelog for 6.3.8 (v6-devel)
Version 6.3.8 [DEVEL] 2012-04-16
- added $PStatJSON directive to permit stats records in JSON format
- added “date-unixtimestamp” property replacer option to format as a unix timestamp (seconds since epoch)
- added “json” property replacer option to support JSON encoding on a per-property basis
- added omhiredis (contributed module)
- added mmjsonparse to support recognizing and parsing JSON enhanced syslog messages
- upgraded more plugins to support the new v6 config format:
– ommysql
– omlibdbi
– omsnmp - added configuration directives to customize queue light delay marks $MainMsgQueueLightDelayMark, $ActionQueueLightDelayMark; both specify number of messages starting at which a delay happens.
- added message property parsesuccess to indicate if the last run higher-level parser could successfully parse the message or not (see property replacer html doc for details)
- bugfix: abort during startup when rsyslog.conf v6+ format was used in a certain way
- bugfix: property $!all-json made rsyslog abort if no normalized data was available
- bugfix: memory leak in array passing output module mode
- added configuration directives to customize queue light delay marks permit size modifiers (k,m,g,…) in integer config parameters
Thanks to Jo Rhett for the suggestion. - bugfix: hostname was not requeried on HUP
Thanks to Per Jessen for reporting this bug and Marius Tomaschewski for his help in testing the fix. - bugfix: imklog invalidly computed facility and severity
closes: http://bugzilla.adiscon.com/show_bug.cgi?id=313 - added configuration directive to disable octet-counted framing for imtcp, directive is $InputTCPServerSupportOctetCountedFraming for imptcp, directive is $InputPTCPServerSupportOctetCountedFraming
- added capability to use a local interface IP address as fromhost-ip for locally originating messages. New directive $LocalHostIPIF