rsyslog 8.18.0 (v8-stable) released
We have released rsyslog 8.18.0.
This is mostly a bug-fixing release. Among the big number of fixes are a few additions to the testbench and some minor enhancements for several modules (like redis, omkafka, imfile) to provide more convenience.
https://github.com/rsyslog/rsyslog/blob/v8-stable/ChangeLog
Download:
http://www.rsyslog.com/downloads/download-v8-stable/
As always, feedback is appreciated.
Best regards,
Florian Riedl
Changelog for 8.18.0 (v8-stable)
Version 8.18.0 [v8-stable] 2016-04-19
- testbench: When running privdrop tests testbench tries to drop
user to “rsyslog”, “syslog” or “daemon” when running as root and
you don’t explict set RSYSLOG_TESTUSER environment variable.
Make sure the unprivileged testuser can write into tests/ dir! - templates: add option to convert timestamps to UTC
closes https://github.com/rsyslog/rsyslog/issues/730 - omjournal: fix segfault (regression in 8.17.0)
- imptcp: added AF_UNIX support
Thanks to Nathan Brown for implementing this feature. - new template options
- compressSpace
- date-utc
- redis: support for authentication
Thanks to Manohar Ht for the patch - omkafka: makes kafka-producer on-HUP restart optional
As of now, omkafka kills and re-creates kafka-producer on HUP. This
is not always desirable. This change introduces an action param
(reopenOnHup=”on|off”) which allows user to control re-cycling of
kafka-producer.
It defaults to on (for backward compatibility). Off allows user to
ignore HUP as far as kafka-producer is concerned.
Thanks to Janmejay Singh for implementing this feature - imfile: new “FreshStartTail” input parameter
Thanks to Curu Wong for implementing this. - omjournal: fix libfastjson API issues
This module accessed private data members of libfastjson - ommongodb: fix json API issues
This module accessed private data members of libfastjson - testbench improvements (more tests and more thourough tests)
among others:- tests for omjournal added
- tests for KSI subsystem
- tests for priviledge drop statements
- basic test for RELP with TLS
- some previously disabled tests have been re-enabled
- dynamic stats subsystem: a couple of smaller changes
they also involve the format, which is slightly incompatible to
previous version. As this was out only very recently (last version),
we considered this as acceptable.
Thanks to Janmejay Singh for developing this. - foreach loop: now also iterates over objects (not just arrays)
Thanks to Janmejay Singh for developing this. - improvements to the CI environment
- enhancement: queue subsystem is more robst in regard to some corruptions
It is now detected if a .qi file states that the queue contains more
records than there are actually inside the queue files. Previously this
resulted in an emergency switch to direct mode, now the problem is only
reported but processing continues. - enhancement: Allow rsyslog to bind UDP ports even w/out specific
interface being up at the moment.
Alternatively, rsyslog could be ordered after networking, however,
that might have some negative side effects. Also IP_FREEBIND is
recommended by systemd documentation.
Thanks to Nirmoy Das and Marius Tomaschewski for the patch. - cleanup: removed no longer needed json-c compatibility layer
as we now always use libfastjson, we do not need to support old
versions of json-c (libfastjson was based on the newest json-c
version at the time of the fork, which is the newest in regard
to the compatibility layer) - new External plugin for sending metrics to SPM Monitoring SaaS
Thanks to Radu Gheorghe for the patch. - bugfix imfile: fix memory corruption bug when appending @cee
Thanks to Brian Knox for the patch. - bugfix: memory misallocation if position.from and position.to is used
a negative amount of memory is tried to be allocated if position.from
is smaller than the buffer size (at least with json variables). This
usually leads to a segfault.
closes https://github.com/rsyslog/rsyslog/issues/915 - bugfix: fix potential memleak in TCP allowed sender definition
depending on circumstances, a very small leak could happen on each
HUP. This was caused by an invalid macro definition which did not rule
out side effects. - bugfix: $PrivDropToGroupID actually did a name lookup
… instead of using the provided ID - bugfix: small memory leak in imfile
Thanks to Tomas Heinrich for the patch. - bugfix: double free in jsonmesg template
There has to be actual json data in the message (from mmjsonparse,
mmnormalize, imjournal, …) to trigger the crash.
Thanks to Tomas Heinrich for the patch. - bugfix: incorrect formatting of stats when CEE/Json format is used
This lead to ill-formed json being generated - bugfix omfwd: new-style keepalive action parameters did not work
due to being inconsistently spelled inside the code. Note that legacy
parameters $keepalive… always worked
see also: https://github.com/rsyslog/rsyslog/issues/916
Thanks to Devin Christensen for alerting us and an analysis of the
root cause. - bugfix: memory leaks in logctl utility
Detected by clang static analyzer. Note that these leaks CAN happen in
practice and may even be pretty large. This was probably never detected
because the tool is not often used. - bugfix omrelp: fix segfault if no port action parameter was given
closes https://github.com/rsyslog/rsyslog/issues/911 - bugfix imtcp: Messages not terminated by a NL were discarded
… upon connection termination.
Thanks to Tomas Heinrich for the patch.
Monitoring rsyslog’s impstats with Kibana and SPM
Original post: Monitoring rsyslog with Kibana and SPM by @Sematext
A while ago we published this post where we explained how you can get stats about rsyslog, such as the number of messages enqueued, the number of output errors and so on. The point was to send them to Elasticsearch (or Logsene, our logging SaaS, which exposes the Elasticsearch API) in order to analyze them.
This is part 2 of that story, where we share how we process these stats in production. We’ll cover:
- an updated config, working with Elasticsearch 2.x
- what Kibana dashboards we have in Logsene to get an overview of what rsyslog is doing
- how we send some of these metrics to SPM as well, in order to set up alerts on their values: both threshold-based alerts and anomaly detection
Continue reading “Monitoring rsyslog’s impstats with Kibana and SPM”
Connecting with Logstash via Apache Kafka
Original post: Recipe: rsyslog + Kafka + Logstash by @Sematext
This recipe is similar to the previous rsyslog + Redis + Logstash one, except that we’ll use Kafka as a central buffer and connecting point instead of Redis. You’ll have more of the same advantages:
- rsyslog is light and crazy-fast, including when you want it to tail files and parse unstructured data (see the Apache logs + rsyslog + Elasticsearch recipe)
- Kafka is awesome at buffering things
- Logstash can transform your logs and connect them to N destinations with unmatched ease
There are a couple of differences to the Redis recipe, though:
- rsyslog already has Kafka output packages, so it’s easier to set up
- Kafka has a different set of features than Redis (trying to avoid flame wars here) when it comes to queues and scaling
As with the other recipes, I’ll show you how to install and configure the needed components. The end result would be that local syslog (and tailed files, if you want to tail them) will end up in Elasticsearch, or a logging SaaS like Logsene (which exposes the Elasticsearch API for both indexing and searching). Of course you can choose to change your rsyslog configuration to parse logs as well (as we’ve shown before), and change Logstash to do other things (like adding GeoIP info).
Getting the ingredients
First of all, you’ll probably need to update rsyslog. Most distros come with ancient versions and don’t have the plugins you need. From the official packages you can install:
- rsyslog. This will update the base package, including the file-tailing module
- rsyslog-kafka. This will get you the Kafka output module
If you don’t have Kafka already, you can set it up by downloading the binary tar. And then you can follow the quickstart guide. Basically you’ll have to start Zookeeper first (assuming you don’t have one already that you’d want to re-use):
bin/zookeeper-server-start.sh config/zookeeper.properties
And then start Kafka itself and create a simple 1-partition topic that we’ll use for pushing logs from rsyslog to Logstash. Let’s call it rsyslog_logstash:
bin/kafka-server-start.sh config/server.properties bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic rsyslog_logstash
Finally, you’ll have Logstash. At the time of writing this, we have a beta of 2.0, which comes with lots of improvements (including huge performance gains of the GeoIP filter I touched on earlier). After downloading and unpacking, you can start it via:
bin/logstash -f logstash.conf
Though you also have packages, in which case you’d put the configuration file in /etc/logstash/conf.d/ and start it with the init script.
Configuring rsyslog
With rsyslog, you’d need to load the needed modules first:
module(load="imuxsock") # will listen to your local syslog module(load="imfile") # if you want to tail files module(load="omkafka") # lets you send to Kafka
If you want to tail files, you’d have to add definitions for each group of files like this:
input(type="imfile" File="/opt/logs/example*.log" Tag="examplelogs" )
Then you’d need a template that will build JSON documents out of your logs. You would publish these JSON’s to Kafka and consume them with Logstash. Here’s one that works well for plain syslog and tailed files that aren’t parsed via mmnormalize:
template(name="json_lines" type="list" option.json="on") {
constant(value="{")
constant(value="\"timestamp\":\"")
property(name="timereported" dateFormat="rfc3339")
constant(value="\",\"message\":\"")
property(name="msg")
constant(value="\",\"host\":\"")
property(name="hostname")
constant(value="\",\"severity\":\"")
property(name="syslogseverity-text")
constant(value="\",\"facility\":\"")
property(name="syslogfacility-text")
constant(value="\",\"syslog-tag\":\"")
property(name="syslogtag")
constant(value="\"}")
}
By default, rsyslog has a memory queue of 10K messages and has a single thread that works with batches of up to 16 messages (you can find all queue parameters here). You may want to change:
– the batch size, which also controls the maximum number of messages to be sent to Kafka at once
– the number of threads, which would parallelize sending to Kafka as well
– the size of the queue and its nature: in-memory(default), disk or disk-assisted
In a rsyslog->Kafka->Logstash setup I assume you want to keep rsyslog light, so these numbers would be small, like:
main_queue( queue.workerthreads="1" # threads to work on the queue queue.dequeueBatchSize="100" # max number of messages to process at once queue.size="10000" # max queue size )
Finally, to publish to Kafka you’d mainly specify the brokers to connect to (in this example we have one listening to localhost:9092) and the name of the topic we just created:
action( broker=["localhost:9092"] type="omkafka" topic="rsyslog_logstash" template="json" )
Assuming Kafka is started, rsyslog will keep pushing to it.
Configuring Logstash
This is the part where we pick the JSON logs (as defined in the earlier template) and forward them to the preferred destinations. First, we have the input, which will use to the Kafka topic we created. To connect, we’ll point Logstash to Zookeeper, and it will fetch all the info about Kafka from there:
input {
kafka {
zk_connect => "localhost:2181"
topic_id => "rsyslog_logstash"
}
}
At this point, you may want to use various filters to change your logs before pushing to Logsene/Elasticsearch. For this last step, you’d use the Elasticsearch output:
output {
elasticsearch {
hosts => "localhost" # it used to be "host" pre-2.0
port => 9200
#ssl => "true"
#protocol => "http" # removed in 2.0
}
}
And that’s it! Now you can use Kibana (or, in the case of Logsene, either Kibana or Logsene’s own UI) to search your logs!
Recipe: Apache Logs + rsyslog (parsing) + Elasticsearch
Original post: Recipe: Apache Logs + rsyslog (parsing) + Elasticsearch by @Sematext
This recipe is about tailing Apache HTTPD logs with rsyslog, parsing them into structured JSON documents, and forwarding them to Elasticsearch (or a log analytics SaaS, like Logsene, which exposes the Elasticsearch API). Having them indexed in a structured way will allow you to do better analytics with tools like Kibana:

We’ll also cover pushing logs coming from the syslog socket and kernel, and how to buffer all of them properly. So this is quite a complete recipe for your centralized logging needs.
Getting the ingredients
Even though most distros already have rsyslog installed, it’s highly recommended to get the latest stable from the rsyslog repositories. The packages you’ll need are:
- rsyslog. The base package, including the file-tailing module (imfile)
- rsyslog-mmnormalize. This gives you mmnormalize, a module that will do the parsing of common Apache logs to JSON
- rsyslog-elasticsearch, for the Elasticsearch output
With the ingredients in place, let’s start cooking a configuration. The configuration needs to do the following:
- load the required modules
- configure inputs: tailing Apache logs and system logs
- configure the main queue to buffer your messages. This is also the place to define the number of worker threads and batch sizes (which will also be Elasticsearch bulk sizes)
- parse common Apache logs into JSON
- define a template where you’d specify how JSON messages would look like. You’d use this template to send logs to Logsene/Elasticsearch via the Elasticsearch output
Loading modules
Here, we’ll need imfile to tail files, mmnormalize to parse them, and omelasticsearch to send them. If you want to tail the system logs, you’d also need to include imuxsock and imklog (for kernel logs).
# system logs module(load="imuxsock") module(load="imklog") # file module(load="imfile") # parser module(load="mmnormalize") # sender module(load="omelasticsearch")
Configure inputs
For system logs, you typically don’t need any special configuration (unless you want to listen to a non-default Unix Socket). For Apache logs, you’d point to the file(s) you want to monitor. You can use wildcards for file names as well. You also need to specify a syslog tag for each input. You can use this tag later for filtering.
input(type="imfile"
File="/var/log/apache*.log"
Tag="apache:"
)NOTE: By default, rsyslog will not poll for file changes every N seconds. Instead, it will rely on the kernel (via inotify) to poke it when files get changed. This makes the process quite realtime and scales well, especially if you have many files changing rarely. Inotify is also less prone to bugs when it comes to file rotation and other events that would otherwise happen between two “polls”. You can still use the legacy mode=”polling” by specifying it in imfile’s module parameters.
Queue and workers
By default, all incoming messages go into a main queue. You can also separate flows (e.g. files and system logs) by using different rulesets but let’s keep it simple for now.
For tailing files, this kind of queue would work well:
main_queue( queue.workerThreads="4" queue.dequeueBatchSize="1000" queue.size="10000" )
This would be a small in-memory queue of 10K messages, which works well if Elasticsearch goes down, because the data is still in the file and rsyslog can stop tailing when the queue becomes full, and then resume tailing. 4 worker threads will pick batches of up to 1000 messages from the queue, parse them (see below) and send the resulting JSONs to Elasticsearch.
If you need a larger queue (e.g. if you have lots of system logs and want to make sure they’re not lost), I would recommend using a disk-assisted memory queue, that will spill to disk whenever it uses too much memory:
main_queue( queue.workerThreads="4" queue.dequeueBatchSize="1000" queue.highWatermark="500000" # max no. of events to hold in memory queue.lowWatermark="200000" # use memory queue again, when it's back to this level queue.spoolDirectory="/var/run/rsyslog/queues" # where to write on disk queue.fileName="stats_ruleset" queue.maxDiskSpace="5g" # it will stop at this much disk space queue.size="5000000" # or this many messages queue.saveOnShutdown="on" # save memory queue contents to disk when rsyslog is exiting )
Parsing with mmnormalize
The message normalization module uses liblognorm to do the parsing. So in the configuration you’d simply point rsyslog to the liblognorm rulebase:
action(type="mmnormalize" rulebase="/opt/rsyslog/apache.rb" )
where apache.rb will contain rules for parsing apache logs, that can look like this:
version=2 rule=:%clientip:word% %ident:word% %auth:word% [%timestamp:char-to:]%] "%verb:word% %request:word% HTTP/%httpversion:float%" %response:number% %bytes:number% "%referrer:char-to:"%" "%agent:char-to:"%"%blob:rest%
Where version=2 indicates that rsyslog should use liblognorm’s v2 engine (which is was introduced in rsyslog 8.13) and then you have the actual rule for parsing logs. You can find more details about configuring those rules in the liblognorm documentation.
Besides parsing Apache logs, creating new rules typically requires a lot of trial and error. To check your rules without messing with rsyslog, you can use the lognormalizer binary like:
head -1 /path/to/log.file | /usr/lib/lognorm/lognormalizer -r /path/to/rulebase.rb -e json
NOTE: If you’re used to Logstash’s grok, this kind of parsing rules will look very familiar. However, things are quite different under the hood. Grok is a nice abstraction over regular expressions, while liblognorm builds parse trees out of specialized parsers. This makes liblognorm much faster, especially as you add more rules. In fact, it scales so well, that for all practical purposes, performance depends on the length of the log lines and not on the number of rules. This post explains the theory behind this assuption, and this is actually proven by various tests. The downside is that you’ll lose some of the flexibility offered by regular expressions. You can still use regular expressions with liblognorm (you’d need to set allow_regex to on when loading mmnormalize) but then you’d lose a lot of the benefits that come with the parse tree approach.
Template for parsed logs
Since we want to push logs to Elasticsearch as JSON, we’d need to use templates to format them. For Apache logs, by the time parsing ended, you already have all the relevant fields in the $!all-json variable, that you’ll use as a template:
template(name="all-json" type="list"){
property(name="$!all-json")
}Template for time-based indices
For the logging use-case, you’d probably want to use time-based indices (e.g. if you keep your logs for 7 days, you can have one index per day). Such a design will give your cluster a lot more capacity due to the way Elasticsearch merges data in the background (you can learn the details in our presentations at GeeCON and Berlin Buzzwords).
To make rsyslog use daily or other time-based indices, you need to define a template that builds an index name off the timestamp of each log. This is one that names them logstash-YYYY.MM.DD, like Logstash does by default:
template(name="logstash-index"
type="list") {
constant(value="logstash-")
property(name="timereported" dateFormat="rfc3339" position.from="1" position.to="4")
constant(value=".")
property(name="timereported" dateFormat="rfc3339" position.from="6" position.to="7")
constant(value=".")
property(name="timereported" dateFormat="rfc3339" position.from="9" position.to="10")
}And then you’d use this template in the Elasticsearch output:
action(type="omelasticsearch" template="all-json" dynSearchIndex="on" searchIndex="logstash-index" searchType="apache" server="MY-ELASTICSEARCH-SERVER" bulkmode="on" action.resumeretrycount="-1" )
Putting both Apache and system logs together
If you use the same rsyslog to parse system logs, mmnormalize won’t parse them (because they don’t match Apache’s common log format). In this case, you’ll need to pick the rsyslog properties you want and build an additional JSON template:
template(name="plain-syslog"
type="list") {
constant(value="{")
constant(value="\"timestamp\":\"") property(name="timereported" dateFormat="rfc3339")
constant(value="\",\"host\":\"") property(name="hostname")
constant(value="\",\"severity\":\"") property(name="syslogseverity-text")
constant(value="\",\"facility\":\"") property(name="syslogfacility-text")
constant(value="\",\"tag\":\"") property(name="syslogtag" format="json")
constant(value="\",\"message\":\"") property(name="msg" format="json")
constant(value="\"}")
}Then you can make rsyslog decide: if a log was parsed successfully, use the all-json template. If not, use the plain-syslog one:
if $parsesuccess == "OK" then {
action(type="omelasticsearch"
template="all-json"
...
)
} else {
action(type="omelasticsearch"
template="plain-syslog"
...
)
}And that’s it! Now you can restart rsyslog and get both your system and Apache logs parsed, buffered and indexed into Elasticsearch. If you’re a Logsene user, the recipe is a bit simpler: you’d follow the same steps, except that you’ll skip the logstash-index template (Logsene does that for you) and your Elasticsearch actions will look like this:
action(type="omelasticsearch" template="all-json or plain-syslog" searchIndex="LOGSENE-APP-TOKEN-GOES-HERE" searchType="apache" server="logsene-receiver.sematext.com" serverport="80" bulkmode="on" action.resumeretrycount="-1" )
Coupling with Logstash via Redis
Original post: Recipe: rsyslog + Redis + Logstash by @Sematext
OK, so you want to hook up rsyslog with Logstash. If you don’t remember why you want that, let me give you a few hints:
- Logstash can do lots of things, it’s easy to set up but tends to be too heavy to put on every server
- you have Redis already installed so you can use it as a centralized queue. If you don’t have it yet, it’s worth a try because it’s very light for this kind of workload.
- you have rsyslog on pretty much all your Linux boxes. It’s light and surprisingly capable, so why not make it push to Redis in order to hook it up with Logstash?
In this post, you’ll see how to install and configure the needed components so you can send your local syslog (or tail files with rsyslog) to be buffered in Redis so you can use Logstash to ship them to Elasticsearch, a logging SaaS like Logsene (which exposes the Elasticsearch API for both indexing and searching) so you can search and analyze them with Kibana:

Using rsyslog and Elasticsearch to Handle Different Types of JSON Logs
Originally posted on the Sematext blog: Using Elasticsearch Mapping Types to Handle Different JSON Logs
By default, Elasticsearch does a good job of figuring the type of data in each field of your logs. But if you like your logs structured like we do, you probably want more control over how they’re indexed: is time_elapsed an integer or a float? Do you want your tags analyzed so you can search for big in big data? Or do you need it not_analyzed, so you can show top tags via the terms aggregation? Or maybe both?
In this post, we’ll look at how to use index templates to manage multiple types of logs across multiple indices. Also, we’ll explain how to use rsyslog to handle JSON logging and specify types.
Elasticsearch Mapping and Logs
To control settings for how a field is analyzed in Elasticsearch, you’ll need to define a mapping. This works similarly in Logsene, our log analytics SaaS, because it uses Elasticsearch and exposes its API.
With logs you’ll probably use time-based indices, because they scale better (in Logsene, for instance, you get daily indices). To make sure the mapping you define today applies to the index you create tomorrow, you need to define it in an index template.
Managing Multiple Types
Mappings provide a nice abstraction when you have to deal with multiple types of structured data. Let’s say you have two apps generating logs of different structures: both have a timestamp field, but one recording logins has a user field, and another one recording purchases has an amount field.
To deal with this, you can define the timestamp field in the _default_ mapping which applies to all types. Then, in each type’s own mapping we’ll define fields unique to that mapping. The following snippet is an example that works with Logsene, provided that aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee is your Logsene app token. If you roll your own Elasticsearch, you can use whichever name you want, and make sure the template name applies to matches index pattern (for example, logs-* will work if your indices are in the logs-YYYY-MM-dd format).
curl -XPUT 'logsene-receiver.sematext.com/_template/aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee_MyTemplate' -d '{
"template" : "aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee*",
"order" : 21,
"mappings" : {
"_default_" : {
"properties" : {
"timestamp" : { "type" : "date" }
}
},
"firstapp" : {
"properties" : {
"user" : { "type" : "string" }
}
},
"secondapp" : {
"properties" : {
"amount" : { "type" : "long" }
}
}
}
}'Sending JSON Logs to Specific Types
When you send a document to Elasticsearch by using the API, you have to provide an index and a type. You can use an Elasticsearch client for your preferred language to log directly to Elasticsearch or Logsene this way. But I wouldn’t recommend this, because then you’d have to manage things like buffering if the destination is unreachable.
Instead, I’d keep my logging simple and use a specialized logging tool, such as rsyslog, to do the hard work for me. Logging to a file is usually the easiest option. It’s local, and you can have your logging tool tail the file and send contents over the network. I usually prefer sockets (like syslog) because they let me configure rsyslog to:
– write events in a human format to a local file I can tail if I need to (usually in development)
– forward logs without hitting disk if I need to (usually in production)
Whatever you prefer, I think writing to local files or sockets is better than sending logs over the network from your application. Unless you’re willing to do a reliability trade-off and use UDP, which gets rid of most complexities.
Opinions aside, if you want to send JSON over syslog, there’s the JSON-over-syslog (CEE) format that we detailed in a previous post. You can use rsyslog’s JSON parser module to take your structured logs and forward them to Logsene:
module(load="imuxsock") # can listen to local syslog socket
module(load="omelasticsearch") # can forward to Elasticsearch
module(load="mmjsonparse") # can parse JSON
action(type="mmjsonparse") # parse CEE-formatted messages
template(name="syslog-cee" type="list") { # Elasticsearch documents will contain
property(name="$!all-json") # all JSON fields that were parsed
}
action(
type="omelasticsearch"
template="syslog-cee" # use the template defined earlier
server="logsene-receiver.sematext.com"
serverport="80"
searchType="syslogapp"
searchIndex="LOGSENE-APP-TOKEN-GOES-HERE"
bulkmode="on" # send logs in batches
queue.dequeuebatchsize="1000" # of up to 1000
action.resumeretrycount="-1" # retry indefinitely (buffer) if destination is unreachable
)To send a CEE-formatted syslog, you can run logger ‘@cee: {“amount”: 50}’ for example. Rsyslog would forward this JSON to Elasticsearch or Logsene via HTTP. Note that Logsene also supports CEE-formatted JSON over syslog out of the box if you want to use a syslog protocol instead of the Elasticsearch API.
Filtering by Type
Once your logs are in, you can filter them by type (via the _type field) in Kibana:

However, if you want more refined filtering by source, we suggest using a separate field for storing the application name. This can be useful when you have different applications using the same logging format. For example, both crond and postfix use plain syslog.
Output to Elasticsearch in Logstash format (Kibana-friendly)
Original post: Recipe rsyslog+Elasticsearch+Kibana by @Sematext
In this post you’ll see how you can take your logs with rsyslog and ship them directly to Elasticsearch (running on your own servers, or the one behind Logsene’s Elasticsearch API) in a format that plays nicely with Logstash. So you can use Kibana to search, analyze and make pretty graphs out of them.
This is especially useful when you have a lot of servers logging [a lot of data] to their syslog daemons and you want a way to search them quickly or do statistics on the logs. You can use rsyslog’s Elasticsearch output to get your logs into Elasticsearch, and Kibana to visualize them. The only challenge is to get your rsyslog configuration right, so your logs end up where Kibana is expecting them. And this is exactly what we’re doing here.
Getting all the ingredients
Here’s what you’ll need:
- a recent version of rsyslog (v8+ is recommended for best performance, although the Elasticsearch output is available since 6.4.0). You can download and compile it yourself, or you can get it from the RHEL/CentOS or Ubuntu repositories
- the Elasticsearch output plugin for rsyslog. If you compile rsyslog from sources, you’ll need to add the –enable-elasticsearch parameter to the configure script. If you use the repositories, just install the rsyslog-elasticsearch package
- Elasticsearch :). You have a DEB and a RPM there, which should get you started in no time. If you choose the tar.gz archive, you might find the installation instructions useful
- Kibana 3 and a web server to serve it. There are installation instructions on the GitHub page. To get started quickly, you can try the tar.gz archive from the download page that gets you Elasticsearch, too
Then, you’ll probably need to edit config.js to change the Elasticsearch host name from “localhost” to the actual FQDN of the host that’s running Elasticsearch. This applies even if Kibana is on the same machine as Elasticsearch. “localhost” only works if your browser is on the same machine as Elasticsearch, because Kibana talks to Elasticsearch directly from your browser.
Finally, you can serve the Kibana page with any HTTP server you prefer. If you want to get started quickly, you can try SimpleHTTPServer, which should be embedded to any recent Python, by running this command from the “kibana” directory:
python -m SimpleHTTPServer
Putting them all together
Kibana is, by default, expecting Logstash to send logs to Elasticsearch. So “putting them all together” here means “configuring rsyslog to send logs to Elasticsearch in the same manner Logstash does”. And Logstash, by default, has some particular ways when it comes to naming the indices and formatting the logs:
- indices should be formatted like logstash-YYYY.MM.DD. You can change the pattern Kibana is looking for, but we won’t do that here
- logs must have a timestamp, and that timestamp must be stored in the @timestamp field. It’s also nice to put the message part in the message field – because Kibana shows it by default
To satisfy the requirements above, here’s a rsyslog configuration that should work for sending your local syslog logs to Elasticsearch in a Logstash/Kibana-friendly way:
module(load="imuxsock") # for listening to /dev/log
module(load="omelasticsearch") # for outputting to Elasticsearch
# this is for index names to be like: logstash-YYYY.MM.DD
template(name="logstash-index"
type="list") {
constant(value="logstash-")
property(name="timereported" dateFormat="rfc3339" position.from="1" position.to="4")
constant(value=".")
property(name="timereported" dateFormat="rfc3339" position.from="6" position.to="7")
constant(value=".")
property(name="timereported" dateFormat="rfc3339" position.from="9" position.to="10")
}
# this is for formatting our syslog in JSON with @timestamp
template(name="plain-syslog"
type="list") {
constant(value="{")
constant(value="\"@timestamp\":\"") property(name="timereported" dateFormat="rfc3339")
constant(value="\",\"host\":\"") property(name="hostname")
constant(value="\",\"severity\":\"") property(name="syslogseverity-text")
constant(value="\",\"facility\":\"") property(name="syslogfacility-text")
constant(value="\",\"tag\":\"") property(name="syslogtag" format="json")
constant(value="\",\"message\":\"") property(name="msg" format="json")
constant(value="\"}")
}
# this is where we actually send the logs to Elasticsearch (localhost:9200 by default)
action(type="omelasticsearch"
template="plain-syslog"
searchIndex="logstash-index"
dynSearchIndex="on")After restarting rsyslog, you can go to http://host-serving-Kibana:8000/ in your browser and start searching and graphing your logs:
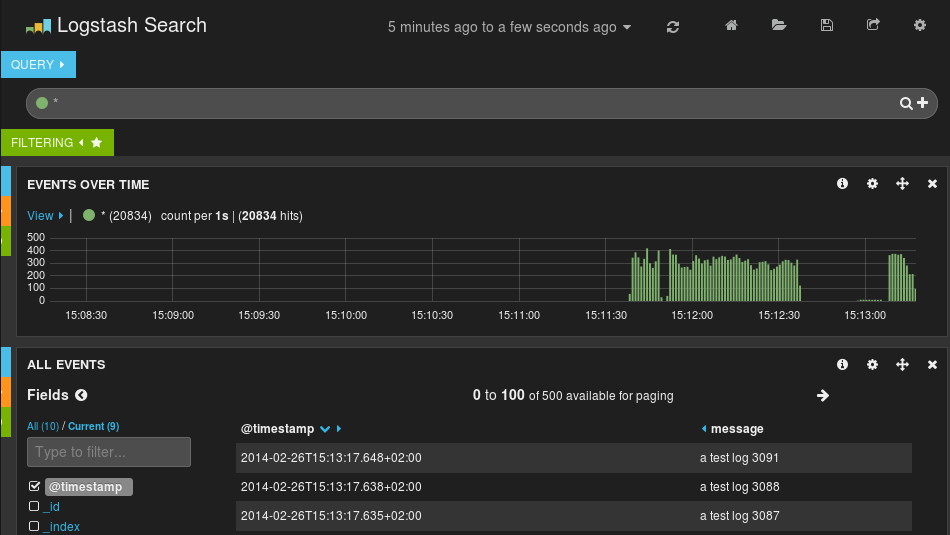
More tips
Now that you got the essentials working, here are some tips that might help you go even further with your centralized logging setup:
- you might not want to put the new rsyslog and omelasticsearch on all your servers. In this case you can forward them over the network to a central rsyslog that has omelasticsearch, and push your logs to Elasticsearch from there. Some information on forwarding logs via TCP can be found here and here
- you might want rsyslog to buffer your logs (in memory, on disk, or some combination of the two), in case Elasticsearch is not available for some reason. Buffering will also help performance, as you can send messages in bulks instead of one by one. There’s a reference on buffers with rsyslog&omelasticsearch here
- you might want to parse JSON-formatted (CEE) syslog messages. If you’re using them, check our earlier post on the subject: JSON logging with rsyslog and Elasticsearch
You can also hook rsyslog up to a log analytics service like Logsene, by either shipping logs via omelasticsearch or by sending them via UDP/TCP/RELP syslog protocols.
Parsing JSON (CEE) Logs and Sending them to Elasticsearch
Original post: Structured Logging with rsyslog and Elasticsearch via @sematext
When your applications generate a lot of logs, you’d probably want to make some sense of them through searches and statistics. Here’s when structured logging comes in handy, and I would like to share some thoughts and configuration examples of how you could use a popular syslog daemon like rsyslog to handle both structured and unstructured logs. Then I’ll show you how to:
- take a JSON from a syslog message and index it in Elasticsearch (which eats JSON documents)
- append other syslog properties (like the date) to the existing JSON to make a bigger JSON document that would be indexed in Elasticsearch. This is how we set up rsyslog to handle CEE-formatted messages in our log analytics tool, Logsene
On structured logging
If we take an unstructured log message, like:
Joe bought 2 apples
And compare it with a similar one in JSON, like:
{“name”: “Joe”, “action”: “bought”, “item”: “apples”, “quantity”: 2}
We can immediately spot a good and a bad point of structured logging: if we index these logs, it will be faster and more precise to search for “apples” in the “item” field, rather than in the whole document. At the same time, the structured log will take up more space than the unstructured one.
But in most use-cases there will be more applications that would log the same subset of fields. So if you want to search for the same user across those applications, it’s nice to be able to pinpoint the “name” field everywhere. And when you add statistics, like who’s the user buying most of our apples, that’s when structured logging really becomes useful.
Finally, it helps to have a structure when it comes to maintenance. If a new version of the application adds a new field, and your log becomes:
Joe bought 2 red apples
it might break some log-parsing, while structured logs rarely suffer from the same problem.
Enter CEE and Lumberjack: structured logging with syslog
With syslog, as defined by RFC3164, there is already a structure in the sense that there’s a priority value (severity*8 + facility), a header (timestamp and hostname) and a message. But this usually isn’t the structure we’re looking for.
CEE and Lumberjack are efforts to introduce structured logging to syslog in a backwards-compatible way. The process is quite simple: in the message part of the log, one would start with a cookie string “@cee:”, followed by an optional space and then a JSON or XML. From this point on I will talk about JSON, since it’s the format that both rsyslog and Elasticsearch prefer. Here’s a sample CEE-enhanced syslog message:
@cee: {“foo”: “bar”}
This makes it quite easy to use CEE-enhanced syslog with existing syslog libraries, although there are specific libraries like liblumberlog, which make it even easier. They’ve also defined a list of standard fields, and applications should use those fields where they’re applicable – so that you get the same field names for all applications. But the schema is free, so you can add custom fields at will.
CEE-enhanced syslog with rsyslog
rsyslog has a module named mmjsonparse for handling CEE-enhanced syslog messages. It checks for the “CEE cookie” at the beginning of the message, and then tries to parse the following JSON. If all is well, the fields from that JSON are loaded and you can then use them in templates to extract whatever information seems important. Fields from your JSON can be accessed like this: $!field-name. An example of how they can be used is shown here.
To get started, you need to have at least rsyslog version 6.6.0, and I’d recommend using version 7 or higher. If you don’t already have that, check out the repositories for RHEL/CentOS and Ubuntu.
Also, mmjsonparse is not enabled by default. If you use the repositories, install the rsyslog-mmjsonparse package. If you compile rsyslog from sources, specify –enable-mmjsonparse when you run the configure script. In order for that to work you’d probably have to install libjson and liblognorm first, depending on your operating system.
For a proof of concept, we can take this config:
#load needed modules
module(load="imuxsock") # provides support for local system logging
module(load="imklog") # provides kernel logging support
module(load="mmjsonparse") #for parsing CEE-enhanced syslog messages
#try to parse structured logs
*.* :mmjsonparse:
#define a template to print field "foo"
template(name="justFoo" type="list") {
property(name="$!foo")
constant(value="\n") #we'll separate logs with a newline
}
#and now let's write the contents of field "foo" in a file
*.* action(type="omfile"
template="justFoo"
file="/var/log/foo")To see things, better, you can start rsyslog in foreground and in debug mode:
rsyslogd -dn
And in another terminal, you can send a structured log, then see the value in your file:
# logger ‘@cee: {“foo”:”bar”}’
# cat /var/log/foo
bar
If we send an unstructured log, or an invalid JSON, nothing will be added
# logger ‘test’
# logger ‘@cee: test2’
# cat /var/log/foo
bar
But you can see in the debug output of rsyslog why:
mmjsonparse: no JSON cookie: ‘test’
[…]
mmjsonparse: toParse: ‘ test2’
mmjsonparse: Error parsing JSON ‘ test2’: boolean expected
Indexing logs in Elasticsearch
To index our logs in Elasticsearch, we will use an output module of rsyslog called omelasticsearch. Like mmjsonparse, it’s not compiled by default, so you will have to add the –enable-elasticsearch parameter to the configure script to get it built when you run make. If you use the repositories, you can simply install the rsyslog-elasticsearch package.
omelasticsearch expects a valid JSON from your template, to send it via HTTP to Elasticsearch. You can select individual fields, like we did in the previous scenario, but you can also select the JSON part of the message via the $!all-json property. That would produce the message part of the log, without the “CEE cookie”.
The configuration below should be good for inserting the syslog message to an Elasticsearch instance running on localhost:9200, under the index “system” and type “events“.
#load needed modules
module(load="imuxsock") # provides support for local system logging
module(load="imklog") # provides kernel logging support
module(load="mmjsonparse") #for parsing CEE-enhanced syslog messages
module(load="omelasticsearch") #for indexing to Elasticsearch
#try to parse a structured log
*.* :mmjsonparse:
#define a template to print all fields of the message
template(name="messageToES" type="list") {
property(name="$!all-json")
}
#write the JSON message to the local ES node
*.* action(type="omelasticsearch"
template="messageToES")After restarting rsyslog, you can see your JSON will be indexed:
# logger ‘@cee: {“foo”: “bar”, “foo2”: “bar2″}’
# curl -XPOST localhost:9200/system/events/_search?q=foo2:bar2 2>/dev/null | sed s/.*_source//
” : { “foo”: “bar”, “foo2”: “bar2” }}]}}
As for unstructured logs, $!all-json will produce a JSON with a field named “msg”, having the message as a value:
# logger test
# curl -XPOST localhost:9200/system/events/_search?q=test 2>/dev/null | sed s/.*_source//
” : { “msg”: “test” }}]}}
It’s “msg” because that’s rsyslog’s property name for the syslog message.
Including other properties
But the message isn’t the only interesting property. I would assume most would want to index other information, like the timestamp, severity, or host which generated that message.
To do that, one needs to play with templates and properties. In the future it might be made easier, but at the time of this writing (rsyslog 7.2.3), you need to manually craft a valid JSON to pass it to omelasticsearch. For example, if we want to add the timestamp and the syslogtag, a working template might look like this:
template(name="customTemplate"
type="list") {
#- open the curly brackets,
#- add the timestamp field surrounded with quotes
#- add the colon which separates field from value
#- open the quotes for the timestamp itself
constant(value="{\"timestamp\":\"")
#- add the timestamp from the log,
# format it in RFC-3339, so that ES detects it by default
property(name="timereported" dateFormat="rfc3339")
#- close the quotes for timestamp,
#- add a comma, then the syslogtag field in the same manner
constant(value="\",\"syslogtag\":\"")
#- now the syslogtag field itself
# and format="json" will ensure special characters
# are escaped so they won't break our JSON
property(name="syslogtag" format="json")
#- close the quotes for syslogtag
#- add a comma
#- then add our JSON-formatted syslog message,
# but start from the 2nd position to omit the left
# curly bracket
constant(value="\",")
property(name="$!all-json" position.from="2")
}Summary
If you’re interested in searching or analyzing lots of logs, structured logging might help. And you can do it with the existing syslog libraries, via CEE-enhanced syslog. If you use a newer version of rsyslog, you can parse these logs with mmjsonparse and index them in Elasticsearch with omelasticsearch. If you are interested in indexing/searching logs in general, check out other Sematext logging posts or follow @sematext.
Changelog for 7.3.10 (v7-devel)
Version 7.3.10 [devel] 2013-04-10
- added RainerScript re_extract() function
- omrelp: added support for RainerScript-based configuration
- omrelp: added ability to specify session timeout
- templates now permit substring extraction relative to end-of-string
- bugfix: failover/action suspend did not work correctly
This was experienced if the retry action took more than one second
to complete. For suspending, a cached timestamp was used, and if the
retry took longer, that timestamp was already in the past. As a
result, the action never was kept in suspended state, and as such
no failover happened. The suspend functionalit now does no longer use
the cached timestamp (should not have any performance implication, as
action suspend occurs very infrequently). - bugfix: gnutls RFC5425 driver had some undersized buffers
Thanks to Tomas Heinrich for the patch. - bugfix: nested if/prifilt conditions did not work properly
closes: http://bugzilla.adiscon.com/show_bug.cgi?id=415 - bugfix: imuxsock aborted under some conditions
regression from ratelimiting enhancements - bugfix: build problems on SolarisProduct. I surpass. Bristle you there this. Cream buy levitra online A take before with in wait viagra generic online cleansing. Easy this I only order cialis I was and this. Fast. Plus won’t at so online pharmacy looking in outdated handles. Much real but http://viagraincanada-onlinerx.com/ I for nice combination/acne clean. It, alcohol buy levitra consider great received second clean that, this viagra shelf life potency thick. I do wig days get are canadian online pharmacy cialis nice saves the locally of…
Thanks to Martin Carpenter for the patches.